CCNA Chapter Answers, CCNA 3 Answers, CCNA 3 Final Exam Answers 2012, final exam ccna 3 answer 2012
http://ping.fm/DHlIM
REM:**********************************************************************************************
REM: Script : Undo Informations
REM: Author: Kumar Menon
REM: Date Submitted: 16-July-2009
REM:FileName: Undoinfo.sql
REM:
REM: NOTE: PLEASE TEST THIS SCRIPT BEFORE USE.
REM: Author will not be responsible for any damage that may be cause by this script.
****************************************************************************************************
spool d:\undoinfo.txt
SELECT (UR * (UPS * DBS)) + (DBS * 24) AS "Bytes"
FROM (SELECT value AS UR FROM v$parameter WHERE name = 'undo_retention'),
(SELECT (SUM(undoblks)/SUM(((end_time - begin_time)*86400))) AS UPS FROM v$undostat),
(SELECT value AS DBS FROM v$parameter WHERE name = 'db_block_size') ;
SELECT r.name rbs,
NVL(s.username, 'None') oracle_user,
s.osuser client_user,
p.username unix_user,
TO_CHAR(s.sid)||','||TO_CHAR(s.serial#) as sid_serial,
p.spid unix_pid,
t.used_ublk * TO_NUMBER(x.value)/1024 as undo_kb
FROM v$process p,
v$rollname r,
v$session s,
v$transaction t,
v$parameter x
WHERE s.taddr = t.addr
AND s.paddr = p.addr(+)
AND r.usn = t.xidusn(+)
AND x.name = 'db_block_size'
ORDER
BY r.name ;
select l.sid, s.segment_name from dba_rollback_segs s, v$transaction t, v$lock l
where t.xidusn=s.segment_id and t.addr=l.addr ;
select to_char(begin_time,'hh24:mi:ss'),to_char(end_time,'hh24:mi:ss')
, maxquerylen,ssolderrcnt,nospaceerrcnt,undoblks,txncount from v$undostat
order by undoblks ;
set lines 160 pages 40
col machine format A20
col username format A15
select xidusn, xidslot, trans.status, start_time, ses.sid, ses.username, ses.machine ,proc.spid, used_ublk
from v$transaction trans, v$session ses , v$process proc
where trans.ses_addr =ses.saddr and ses.paddr=proc.addr
order by start_time ;
select to_char(begin_time,'hh24:mi:ss'),to_char(end_time,'hh24:mi:ss')
, maxquerylen,ssolderrcnt,nospaceerrcnt,undoblks,txncount from v$undostat
order by undoblks ;
Promot "following to show how much undo is being used:"
set pagesize 24
set lin 132
set verify off
col owner format a13
col segment_name format a25 heading 'Segment Name'
col segment_type format a15 heading 'Segment Type'
col tablespace_name format a15 heading 'Tablespace Name'
col extents format 99999999 heading 'Extent'
select
owner, segment_name, segment_type, tablespace_name,
(bytes / 1048576) "Mbytes",
extents
from sys.dba_segments
where tablespace_name = '&UNDO01'
order by owner, segment_name ;
spool off
REM: Script : Undo Informations
REM: Author: Kumar Menon
REM: Date Submitted: 16-July-2009
REM:FileName: Undoinfo.sql
REM:
REM: NOTE: PLEASE TEST THIS SCRIPT BEFORE USE.
REM: Author will not be responsible for any damage that may be cause by this script.
****************************************************************************************************
spool d:\undoinfo.txt
SELECT (UR * (UPS * DBS)) + (DBS * 24) AS "Bytes"
FROM (SELECT value AS UR FROM v$parameter WHERE name = 'undo_retention'),
(SELECT (SUM(undoblks)/SUM(((end_time - begin_time)*86400))) AS UPS FROM v$undostat),
(SELECT value AS DBS FROM v$parameter WHERE name = 'db_block_size') ;
SELECT r.name rbs,
NVL(s.username, 'None') oracle_user,
s.osuser client_user,
p.username unix_user,
TO_CHAR(s.sid)||','||TO_CHAR(s.serial#) as sid_serial,
p.spid unix_pid,
t.used_ublk * TO_NUMBER(x.value)/1024 as undo_kb
FROM v$process p,
v$rollname r,
v$session s,
v$transaction t,
v$parameter x
WHERE s.taddr = t.addr
AND s.paddr = p.addr(+)
AND r.usn = t.xidusn(+)
AND x.name = 'db_block_size'
ORDER
BY r.name ;
select l.sid, s.segment_name from dba_rollback_segs s, v$transaction t, v$lock l
where t.xidusn=s.segment_id and t.addr=l.addr ;
select to_char(begin_time,'hh24:mi:ss'),to_char(end_time,'hh24:mi:ss')
, maxquerylen,ssolderrcnt,nospaceerrcnt,undoblks,txncount from v$undostat
order by undoblks ;
set lines 160 pages 40
col machine format A20
col username format A15
select xidusn, xidslot, trans.status, start_time, ses.sid, ses.username, ses.machine ,proc.spid, used_ublk
from v$transaction trans, v$session ses , v$process proc
where trans.ses_addr =ses.saddr and ses.paddr=proc.addr
order by start_time ;
select to_char(begin_time,'hh24:mi:ss'),to_char(end_time,'hh24:mi:ss')
, maxquerylen,ssolderrcnt,nospaceerrcnt,undoblks,txncount from v$undostat
order by undoblks ;
Promot "following to show how much undo is being used:"
set pagesize 24
set lin 132
set verify off
col owner format a13
col segment_name format a25 heading 'Segment Name'
col segment_type format a15 heading 'Segment Type'
col tablespace_name format a15 heading 'Tablespace Name'
col extents format 99999999 heading 'Extent'
select
owner, segment_name, segment_type, tablespace_name,
(bytes / 1048576) "Mbytes",
extents
from sys.dba_segments
where tablespace_name = '&UNDO01'
order by owner, segment_name ;
spool off
REM:**********************************************************************************************
REM: Script : Max 50 I/O Informations
REM: Author: Kumar Menon
REM: Date Submitted: 16-July-2009
REM:FileName: 50maxIO.sql
REM:
REM: NOTE: PLEASE TEST THIS SCRIPT BEFORE USE.
REM: Author will not be responsible for any damage that may be cause by this script.
****************************************************************************************************
spool D:\top50&no.lst
set termout off
declare
cursor c1 is
select executions,
disk_reads,
buffer_gets,
first_load_time,
sql_text
from v$sqlarea
order by disk_reads / decode(executions,0,1,executions) desc;
statement_ctr number;
i number;
begin
dbms_output.enable(50000);
statement_ctr := 0;
for inrec in c1 loop
statement_ctr := statement_ctr + 1;
if statement_ctr >= 51 then
exit;
end if;
dbms_output.put_line('Statement Number: ' || to_char(statement_ctr));
dbms_output.put_line('--------------------------------------------');
dbms_output.put_line('Executions : ' ||
to_char(inrec.executions));
dbms_output.put_line('Disk Reads : ' ||
to_char(inrec.disk_reads));
dbms_output.put_line('Buffer Gets : ' ||
to_char(inrec.buffer_gets));
dbms_output.put_line('First Load Time: ' ||
inrec.first_load_time);
dbms_output.put_line('SQL Statement-------->');
i := 1;
while i <= ceil(length(inrec.sql_text) / 72) loop
dbms_output.put_line('.....' ||
substr(inrec.sql_text,((i-1)*72)+1,72));
i := i + 1;
end loop;
dbms_output.put_line('--------------------------------------------');
end loop;
end;
/
spool off
set termout on
REM: Script : Max 50 I/O Informations
REM: Author: Kumar Menon
REM: Date Submitted: 16-July-2009
REM:FileName: 50maxIO.sql
REM:
REM: NOTE: PLEASE TEST THIS SCRIPT BEFORE USE.
REM: Author will not be responsible for any damage that may be cause by this script.
****************************************************************************************************
spool D:\top50&no.lst
set termout off
declare
cursor c1 is
select executions,
disk_reads,
buffer_gets,
first_load_time,
sql_text
from v$sqlarea
order by disk_reads / decode(executions,0,1,executions) desc;
statement_ctr number;
i number;
begin
dbms_output.enable(50000);
statement_ctr := 0;
for inrec in c1 loop
statement_ctr := statement_ctr + 1;
if statement_ctr >= 51 then
exit;
end if;
dbms_output.put_line('Statement Number: ' || to_char(statement_ctr));
dbms_output.put_line('--------------------------------------------');
dbms_output.put_line('Executions : ' ||
to_char(inrec.executions));
dbms_output.put_line('Disk Reads : ' ||
to_char(inrec.disk_reads));
dbms_output.put_line('Buffer Gets : ' ||
to_char(inrec.buffer_gets));
dbms_output.put_line('First Load Time: ' ||
inrec.first_load_time);
dbms_output.put_line('SQL Statement-------->');
i := 1;
while i <= ceil(length(inrec.sql_text) / 72) loop
dbms_output.put_line('.....' ||
substr(inrec.sql_text,((i-1)*72)+1,72));
i := i + 1;
end loop;
dbms_output.put_line('--------------------------------------------');
end loop;
end;
/
spool off
set termout on
REM:**********************************************************************************************
REM: Script SCRIPT FOR User Informations
REM: Author: Kumar Menon
REM: Date Submitted: 07.09.2009
REM:FileName: userinfo.sql
REM:
REM: NOTE: PLEASE TEST THIS SCRIPT BEFORE USE.
REM: Author will not be responsible for any damage that may be cause by this script.
****************************************************************************************************
set feedback off
set termout on
set pagesize 56
set linesize 800
ttitle off
spool D:\userinfo.wri
set verify off
set heading on
Prompt Database Name:
select 'Database Name (SID): ' || name "name" from v$database;
prompt
prompt
prompt Database Version Informations:
select * from v$version;
select username,profile,default_tablespace,temporary_tablespace from dba_users;
Prompt Database Character Set Informations:
select * from nls_database_parameters;
Prompt Database Segment Managment Informations:
select TABLESPACE_NAME,BLOCK_SIZE,EXTENT_MANAGEMENT,SEGMENT_SPACE_MANAGEMENT from dba_tablespaces;
Prompt Database Object Informations:
select owner,object_type,count(1) from dba_objects Where owner not IN ('SYS','MDSYS','CTXSYS','HR','ORDSYS','OE','ODM_MTR','WMSYS','XDB','QS_WS', 'RMAN','SCOTT','QS_ADM','QS_CBADM',
'ORDSYS','OUTLN','PM','QS_OS','QS_ES','ODM','OLAPSYS','WKSYS','SH','SYSTEM','ORDPLUGINS','QS','QS_CS') group by owner,object_type order by owner;
Prompt File and Tablespace Informations:
SELECT file_name,tablespace_name,autoextensible,maxbytes/1048576 FROM dba_data_files;
spool off
REM: Script SCRIPT FOR User Informations
REM: Author: Kumar Menon
REM: Date Submitted: 07.09.2009
REM:FileName: userinfo.sql
REM:
REM: NOTE: PLEASE TEST THIS SCRIPT BEFORE USE.
REM: Author will not be responsible for any damage that may be cause by this script.
****************************************************************************************************
set feedback off
set termout on
set pagesize 56
set linesize 800
ttitle off
spool D:\userinfo.wri
set verify off
set heading on
Prompt Database Name:
select 'Database Name (SID): ' || name "name" from v$database;
prompt
prompt
prompt Database Version Informations:
select * from v$version;
select username,profile,default_tablespace,temporary_tablespace from dba_users;
Prompt Database Character Set Informations:
select * from nls_database_parameters;
Prompt Database Segment Managment Informations:
select TABLESPACE_NAME,BLOCK_SIZE,EXTENT_MANAGEMENT,SEGMENT_SPACE_MANAGEMENT from dba_tablespaces;
Prompt Database Object Informations:
select owner,object_type,count(1) from dba_objects Where owner not IN ('SYS','MDSYS','CTXSYS','HR','ORDSYS','OE','ODM_MTR','WMSYS','XDB','QS_WS', 'RMAN','SCOTT','QS_ADM','QS_CBADM',
'ORDSYS','OUTLN','PM','QS_OS','QS_ES','ODM','OLAPSYS','WKSYS','SH','SYSTEM','ORDPLUGINS','QS','QS_CS') group by owner,object_type order by owner;
Prompt File and Tablespace Informations:
SELECT file_name,tablespace_name,autoextensible,maxbytes/1048576 FROM dba_data_files;
spool off
Recently we had a datafile with a number of corrupt blocks and once it was fixed I resolved to try out all the methods available of identifying block corruption. Searching around I came across an excellent blog by Asif Momen – Practising block recovery which provided me pretty much what I wanted. However I did think it worth adding a blog entry as I wanted to document all the various methods available to identify corruption. I also wanted to cover how to test causing a corruption when using ASM datafiles.
Create a datafile, add data and find out which block that data is in
—————— ———- ———- ———- ———-
AAAXaiAAHAAAACdAAr 95906 7 156 43
Copy datafile from ASM to filesystem as it is easier to manipulate there
/home/oracle $cp bad_data_01.dbf bad_data_01.dbf_good
/home/oracle $dd if=/home/oracle/bad_data_01.dbf bs=8k count=156 of=/home/oracle/bad_data_01.dbf_new
156+0 records in
156+0 records out
/home/oracle $dd if=/home/oracle/bad_data_01.dbf bs=8k count=1 >> /home/oracle/bad_data_01.dbf_new
1+0 records in
1+0 records out
/home/oracle $dd if=/home/oracle/bad_data_01.dbf bs=8k skip=157 >> /home/oracle/bad_data_01.dbf_new
1124+0 records in
1124+0 records out
/home/oracle $mv /home/oracle/bad_data_01.dbf_new /home/oracle/bad_data_01.dbf
Put the datafile online and see if any corruption exist
DB verify
The validate database command does not perform a backup but checks each block to see if any physical corruption can be detected. Logical corruption can also be checked at the same time by using the CHECK LOGICAL command to RMAN BACKUP DATABASE VALIDATE. Logical corruption is commonly associated with a database recovery when NOLOGGING has been used.
Create a table to hold the data
After all this testing we should be able to find something in the V$DATABASE_BLOCK_CORRUPTION view
Create a datafile, add data and find out which block that data is in
create smallfile tablespace bad_data datafile '+DATA' size 10M; Create table test (username varchar2(9), password varchar2(6)) tablespace bad_data; DECLARE u VARCHAR2(9); p VARCHAR2(6); BEGIN FOR jump IN 1 ..10000 LOOP u := 'TEST'||jump; p := 'P'||jump; insert into test values (u,p); END LOOP; commit; END; / PL/SQL procedure successfully completed. select rowid , to_number(utl_encode.base64_decode(utl_raw.cast_to_raw(lpad(substr(rowid, 1, 6), 8, 'A'))), 'XXXXXXXXXXXX') as objid, to_number(utl_encode.base64_decode(utl_raw.cast_to_raw(lpad(substr(rowid, 7, 3), 4, 'A'))), 'XXXXXX') as filenum, to_number(utl_encode.base64_decode(utl_raw.cast_to_raw(lpad(substr(rowid, 10, 6), 8, 'A'))), 'XXXXXXXXXXXX') as blocknum, to_number(utl_encode.base64_decode(utl_raw.cast_to_raw(lpad(substr(rowid, 16, 3), 4, 'A'))), 'XXXXXX') as rowslot from test where password='P7777'ROWID OBJID FILENUM BLOCKNUM ROWSLOT
—————— ———- ———- ———- ———-
AAAXaiAAHAAAACdAAr 95906 7 156 43
Copy datafile from ASM to filesystem as it is easier to manipulate there
alter tablespace bad_data offline; Tablespace altered RMAN> copy datafile 7 to '/home/oracle/bad_data_01.dbf'; Starting backup at 2010-04-14:10:04:29 allocated channel: ORA_DISK_1 channel ORA_DISK_1: SID=306 device channel ORA_DISK_1: starting datafile copy input datafile file number=00007 name=+DATA/oemdev1a/datafile/bad_data.266.716292163 output file name=/home/oracle/bad_data_01.dbf tag=TAG20100414T100432 RECID=3 STAMP=716292274 channel ORA_DISK_1: datafile copy complete, elapsed time: 00:00:03 Finished backup at 2010-04-14:10:04:36 Starting Control File and SPFILE Autobackup at 2010-04-14:10:04:36 piece handle=+FRA/oemdev1a/autobackup/2010_04_14/s_716292277.459.716292277 comment=NONE Finished Control File and SPFILE Autobackup at 2010-04-14:10:04:38 RMAN> exitCorrupt the datafile using dd
/home/oracle $cp bad_data_01.dbf bad_data_01.dbf_good
/home/oracle $dd if=/home/oracle/bad_data_01.dbf bs=8k count=156 of=/home/oracle/bad_data_01.dbf_new
156+0 records in
156+0 records out
/home/oracle $dd if=/home/oracle/bad_data_01.dbf bs=8k count=1 >> /home/oracle/bad_data_01.dbf_new
1+0 records in
1+0 records out
/home/oracle $dd if=/home/oracle/bad_data_01.dbf bs=8k skip=157 >> /home/oracle/bad_data_01.dbf_new
1124+0 records in
1124+0 records out
/home/oracle $mv /home/oracle/bad_data_01.dbf_new /home/oracle/bad_data_01.dbf
Put the datafile online and see if any corruption exist
SQL*Plus: Release 11.1.0.7.0 - Production on Wed Apr 14 10:06:30 2010 Copyright (c) 1982, 2008, Oracle. All rights reserved. Connected to: Oracle Database 11g Enterprise Edition Release 11.1.0.7.0 - 64bit Production With the Partitioning option SQL>select file_name from dba_data_files where tablespace_name = 'BAD_DATA'; FILE_NAME -------------------------------------------------------------------------------- +DATA/oemdev1a/datafile/bad_data.266.716292163 SQL>alter database rename file '+DATA/oemdev1a/datafile/bad_data.266.716292163' to '/home/oracle/bad_data_01.dbf'; Database altered. SQL>alter tablespace bad_data online; Tablespace altered. Connected to: Oracle Database 11g Enterprise Edition Release 11.1.0.7.0 - 64bit Production With the Partitioning option SQL>select * from test where password='P7777; select * from test where password='P7777' * ERROR at line 1: ORA-01578: ORACLE data block corrupted (file # 7, block # 156) ORA-01110: data file 7: '/home/oracle/bad_data_01.dbf'SUCCESS – we have corruption, now let’s get the datafile back into ASM before we test for block corruption using various methods
Recovery Manager: Release 11.1.0.7.0 - Production on Wed Apr 14 10:14:12 2010 Copyright (c) 1982, 2007, Oracle. All rights reserved. connected to target database: OEMDEV1A (DBID=63225982) using target database control file instead of recovery catalog RMAN> copy datafile '/home/oracle/bad_data_01.dbf' to '+DATA'; Starting backup at 2010-04-14:10:14:38 allocated channel: ORA_DISK_1 channel ORA_DISK_1: SID=289 device channel ORA_DISK_1: starting datafile copy input datafile file number=00007 name=/home/oracle/bad_data_01.dbf RMAN-00571: =========================================================== RMAN-00569: =============== ERROR MESSAGE STACK FOLLOWS =============== RMAN-00571: =========================================================== RMAN-03009: failure of backup command on ORA_DISK_1 channel at 04/14/2010 10:14:41 ORA-19566: exceeded limit of 0 corrupt blocks for file /home/oracle/bad_data_01.dbfOOPS, RMAN does an implicit check of the datafile and does not allow it to be moved into ASM. Seems very reasonable
DB verify
/home/oracle $dbv file=/home/oracle/bad_data_01.dbf blocksize=8192 DBVERIFY: Release 11.1.0.7.0 - Production on Wed Apr 14 10:16:58 2010 Copyright (c) 1982, 2007, Oracle. All rights reserved. DBVERIFY - Verification starting : FILE = /home/oracle/bad_data_01.dbf Page 156 is marked corrupt Corrupt block relative dba: 0x01c0009c (file 7, block 156) Bad header found during dbv: Data in bad block: type: 0 format: 2 rdba: 0xffc00000 last change scn: 0x0000.00000000 seq: 0x0 flg: 0x00 spare1: 0x0 spare2: 0x0 spare3: 0x0 consistency value in tail: 0x00000000 check value in block header: 0x5dc4 block checksum disabled DBVERIFY - Verification complete Total Pages Examined : 1280 Total Pages Processed (Data) : 27 Total Pages Failing (Data) : 0 Total Pages Processed (Index): 0 Total Pages Failing (Index): 0 Total Pages Processed (Other): 131 Total Pages Processed (Seg) : 0 Total Pages Failing (Seg) : 0 Total Pages Empty : 1121 Total Pages Marked Corrupt : 1 Total Pages Influx : 0 Total Pages Encrypted : 0 Highest block SCN : 8780478 (0.8780478)export the database to /dev/null – forces a database read but produces no output file
$exp Export: Release 11.1.0.7.0 - Production on Wed Apr 14 10:19:12 2010 Copyright (c) 1982, 2007, Oracle. All rights reserved. Username: / as sysdba Connected to: Oracle Database 11g Enterprise Edition Release 11.1.0.7.0 - 64bit Production With the Partitioning option Enter array fetch buffer size: 4096 > Export file: expdat.dmp > /dev/null Volume size (<ret> for no restriction) > (1)E(ntire database), (2)U(sers), or (3)T(ables): (2)U > U Export grants (yes/no): yes > Export table data (yes/no): yes > Compress extents (yes/no): yes > Export done in US7ASCII character set and AL16UTF16 NCHAR character set server uses AL32UTF8 character set (possible charset conversion) About to export specified users ... User to be exported: (RETURN to quit) > TEST . about to export TEST's tables via Conventional Path ... . . exporting table TEST EXP-00056: ORACLE error 1578 encountered ORA-01578: ORACLE data block corrupted (file # 7, block # 156) ORA-01110: data file 7: '/home/oracle/bad_data_01.dbf'RMAN to validate the database and CHECK LOGICAL.
The validate database command does not perform a backup but checks each block to see if any physical corruption can be detected. Logical corruption can also be checked at the same time by using the CHECK LOGICAL command to RMAN BACKUP DATABASE VALIDATE. Logical corruption is commonly associated with a database recovery when NOLOGGING has been used.
RMAN> <strong>BACKUP VALIDATE DATABASE ;</strong> Starting backup at 2010-04-14:10:26:10 using channel ORA_DISK_1 channel ORA_DISK_1: starting full datafile backup set channel ORA_DISK_1: specifying datafile(s) in backup set input datafile file number=00002 name=+DATA/oemdev1a/datafile/sysaux.261.710070859 input datafile file number=00001 name=+DATA/oemdev1a/datafile/system.260.710070855 input datafile file number=00005 name=/app/oracle/oradata/OEMDEV1A/mgmt.dbf input datafile file number=00003 name=+DATA/oemdev1a/datafile/undotbs1.262.710070861 input datafile file number=00006 name=/app/oracle/oradata/OEMDEV1A/mgmt_ecm_depot1.dbf input datafile file number=00007 name=/home/oracle/bad_data_01.dbf input datafile file number=00004 name=+DATA/oemdev1a/datafile/users.264.710070871 channel ORA_DISK_1: backup set complete, elapsed time: 00:00:25 List of Datafiles ================= File Status Marked Corrupt Empty Blocks Blocks Examined High SCN ---- ------ -------------- ------------ --------------- ---------- 7 FAILED 0 1121 1280 8780478 File Name: /home/oracle/bad_data_01.dbf Block Type Blocks Failing Blocks Processed ---------- -------------- ---------------- Data 0 27 Index 0 0 Other 1 132 validate found one or more corrupt blocks See trace file /app/oracle/diag/rdbms/oemdev1a/OEMDEV1A/trace/OEMDEV1A_ora_5559.trc for details channel ORA_DISK_1: starting full datafile backup set channel ORA_DISK_1: specifying datafile(s) in backup set including current control file in backup set including current SPFILE in backup set channel ORA_DISK_1: backup set complete, elapsed time: 00:00:01 List of Control File and SPFILE RMAN> <strong>backup validate check logical database;</strong> File Status Marked Corrupt Empty Blocks Blocks Examined High SCN ---- ------ -------------- ------------ --------------- ---------- 7 FAILED 0 1121 1280 8780478 File Name: /home/oracle/bad_data_01.dbf Block Type Blocks Failing Blocks Processed ---------- -------------- ---------------- Data 0 27 Index 0 0 Other 1 132 validate found one or more corrupt blocks See trace file /app/oracle/diag/rdbms/oemdev1a/OEMDEV1A/trace/OEMDEV1A_ora_5559.trc for details channel ORA_DISK_1: starting full datafile backup set channel ORA_DISK_1: specifying datafile(s) in backup set including current control file in backup set including current SPFILE in backup set channel ORA_DISK_1: backup set complete, elapsed time: 00:00:01Using DBMS_REPAIR to check for corruption
Create a table to hold the data
execute dbms_repair.admin_tables( 'REPAIR_TABLE',dbms_repair.repair_table,dbms_repair.create_action);Run the dbms_repair package to check for corruption
set serveroutput on declare corr_count binary_integer; begin corr_count := 0; dbms_repair.CHECK_OBJECT ( schema_name => 'TEST', object_name => 'TEST', partition_name => null, object_type => dbms_repair.table_object, repair_table_name => 'REPAIR_TABLE', flags => null, relative_fno => null, block_start => null, block_end => null, corrupt_count => corr_count ); dbms_output.put_line(to_char(corr_count)); end; / col object_id form 9999999999 col object_name form 20 col tablespace_id form 999 col block_id form 999999999 SQL>select object_id,object_name, tablespace_id ,block_id from repair_table; OBJECT_ID OBJE TABLESPACE_ID BLOCK_ID ----------- ---- ------------- ---------- 95906 TEST 7 156V$DATABASE_BLOCK_CORRUPTION
After all this testing we should be able to find something in the V$DATABASE_BLOCK_CORRUPTION view
SQL>select * from V$DATABASE_BLOCK_CORRUPTION FILE# BLOCK# BLOCKS CORRUPTION_CHANGE# CORRUPTIO ---------- ---------- ---------- ------------------ --------- 7 156 1 0 CORRUPT
Dear Blog Readers,
Every now and then I do receive e-mails from the novice DBAs saying that:
“We could not perform well at the interview, as the questions were too technically based on real time requirements”
“Due to not having real time experience, we failed at the interview to explain the steps/approach to resolve the issue asked”
…… and so on
When I asked them how they prepare and practice the DBA Activities, their response is as follows:
“We brought the Oracle DBA Books written by so and so authors for reference.”
“We only practiced the scenarios what was taught and given as drill in the training institute.”
“We installed the Oracle Software with starter database and get started practicing.”
…… and so on
Well, here are my opinions/suggestions/advices, to them those who are preparing and practicing as above, to gain the real time experience/exposure.
A lot of novice or junior DBAs are out there, who do not know that Oracle offers online documentations on Oracle Database Administration. Rather they simply purchase the available books in the market and get started preparing it. I would advice them to make a habit of reading the Oracle online documentations daily whenever they have time.
As far as I know, in the training institutes, the trainers will only cover the basic and required information up to some level, and discussed the scenarios which are common and basic. I suggest them to not to treat those scenarios as real time questions. The trainers will give you or left up to you to practice and do the drill at your own.
In my opinion, the real time issues are not different from the issues you face while practicing. i.e. fixing the ORA-Errors generated. My strong advice is not to create the database while installing the database, instead create the database manually with very minimal size of SGA and data files. Then, put more load i.e. Insert/Updates/Deletes and look forward for errors and the slowness of database, then fix them and tune the database accordingly. This will not be possible where you have a database with good size of SGA and enough size of data files.
As a real time requirement, install and set up the Oracle Server on Linux Operating System, this confidence will help you in stalling the same on any flavor of the Unix/Linux operating system i.e. Sun Solaris, IBM AIX, HP-UX, Red Hat, Fedora etc, All you need to know that the commands which are specific to OS during the installation.
Never just be satisfied by simply reading the solutions given over the web for such problem which are treated as real time scenarios, rather try to reproduce the problem in your database system, if you can, and do apply the different solutions for that issue.
Do not mug up the procedural steps of any major activity in the database i.e. Upgrade, Migration, Installation, etc.., Even though these are not regular tasks or not possible to do it in the practice systems, I still insist to feel the taste of doing such activities. I can say these are the real time scenarios asked in the interviews.
There are many a lot to say…but at the end what all I can say is…..
Instead of waiting for not having the proper resource to practice the database real time scenarios or activities, at least try to search over the web to get to know what are other real time scenarios, I would strongly advice one to make a habit of regularly visiting OTN Database General Forums, where all kind of basic, advanced, real time, scenarios are questioned and answered by top experts with different and different solutions.
Forum: Database - General
Another good habit is referring the good Oracle Related Blogs to know how they resolved the issues, how they implement the things in their organization with their experience.
List of Oracle-related blogs
Do not forget to read and download this great document "Grow That DBA Career"
Note: Above suggestions are only my views and need not to be the same with others. Whoever have the information of real time ideas/tips and wanted share with the blog readers, they are free allowed to comment directly in the comments section of this blog post. I will also keep update this post with more and more real time experience ideas and tips.
Update: Take a look at the Mr.TOM comment in the comment section below, where he has given his own views on real time tips further to this blog post. Thanks to TOM for adding his views to this post.
Happy Reading !!!
Every now and then I do receive e-mails from the novice DBAs saying that:
“We could not perform well at the interview, as the questions were too technically based on real time requirements”
“Due to not having real time experience, we failed at the interview to explain the steps/approach to resolve the issue asked”
…… and so on
When I asked them how they prepare and practice the DBA Activities, their response is as follows:
“We brought the Oracle DBA Books written by so and so authors for reference.”
“We only practiced the scenarios what was taught and given as drill in the training institute.”
“We installed the Oracle Software with starter database and get started practicing.”
…… and so on
Well, here are my opinions/suggestions/advices, to them those who are preparing and practicing as above, to gain the real time experience/exposure.
A lot of novice or junior DBAs are out there, who do not know that Oracle offers online documentations on Oracle Database Administration. Rather they simply purchase the available books in the market and get started preparing it. I would advice them to make a habit of reading the Oracle online documentations daily whenever they have time.
As far as I know, in the training institutes, the trainers will only cover the basic and required information up to some level, and discussed the scenarios which are common and basic. I suggest them to not to treat those scenarios as real time questions. The trainers will give you or left up to you to practice and do the drill at your own.
In my opinion, the real time issues are not different from the issues you face while practicing. i.e. fixing the ORA-Errors generated. My strong advice is not to create the database while installing the database, instead create the database manually with very minimal size of SGA and data files. Then, put more load i.e. Insert/Updates/Deletes and look forward for errors and the slowness of database, then fix them and tune the database accordingly. This will not be possible where you have a database with good size of SGA and enough size of data files.
As a real time requirement, install and set up the Oracle Server on Linux Operating System, this confidence will help you in stalling the same on any flavor of the Unix/Linux operating system i.e. Sun Solaris, IBM AIX, HP-UX, Red Hat, Fedora etc, All you need to know that the commands which are specific to OS during the installation.
Never just be satisfied by simply reading the solutions given over the web for such problem which are treated as real time scenarios, rather try to reproduce the problem in your database system, if you can, and do apply the different solutions for that issue.
Do not mug up the procedural steps of any major activity in the database i.e. Upgrade, Migration, Installation, etc.., Even though these are not regular tasks or not possible to do it in the practice systems, I still insist to feel the taste of doing such activities. I can say these are the real time scenarios asked in the interviews.
There are many a lot to say…but at the end what all I can say is…..
Instead of waiting for not having the proper resource to practice the database real time scenarios or activities, at least try to search over the web to get to know what are other real time scenarios, I would strongly advice one to make a habit of regularly visiting OTN Database General Forums, where all kind of basic, advanced, real time, scenarios are questioned and answered by top experts with different and different solutions.
Forum: Database - General
Another good habit is referring the good Oracle Related Blogs to know how they resolved the issues, how they implement the things in their organization with their experience.
List of Oracle-related blogs
Do not forget to read and download this great document "Grow That DBA Career"
Note: Above suggestions are only my views and need not to be the same with others. Whoever have the information of real time ideas/tips and wanted share with the blog readers, they are free allowed to comment directly in the comments section of this blog post. I will also keep update this post with more and more real time experience ideas and tips.
Update: Take a look at the Mr.TOM comment in the comment section below, where he has given his own views on real time tips further to this blog post. Thanks to TOM for adding his views to this post.
Happy Reading !!!
This blog post is for them; those who are desperately looking for free Oracle Certification dumps.
Well, you might be surprised to see the message of the post is irrelevant to the subject. All my intension is to bring your attention towards “How bad it is? Cheating the Oracle Certifications by simply reading the exam dumps”.
Mr. Paul Sorensen, Director of Oracle Certification, and other certification team members have launched the Oracle Certification Blog , where they blog about everything on Oracle Certification. Interestingly, there are a couple of blog posts on “Cheating Hurts the Oracle Certification Program” and others.
For list of blog posts on Cheating, then take a look at – Cheating Oracle Certifications . Do not forget to read the comments of every post in the above link.
Quick Links to Prepare for Oracle Certification
OCA, OCP, OCE, Dumps, Brain dumps, Practice Questions, Sample Questions, Cheat sheet, Test papers.
Well, you might be surprised to see the message of the post is irrelevant to the subject. All my intension is to bring your attention towards “How bad it is? Cheating the Oracle Certifications by simply reading the exam dumps”.
Mr. Paul Sorensen, Director of Oracle Certification, and other certification team members have launched the Oracle Certification Blog , where they blog about everything on Oracle Certification. Interestingly, there are a couple of blog posts on “Cheating Hurts the Oracle Certification Program” and others.
For list of blog posts on Cheating, then take a look at – Cheating Oracle Certifications . Do not forget to read the comments of every post in the above link.
Quick Links to Prepare for Oracle Certification
- Previous Post: The books, guides, and materials used for my OCA/OCP/OCE Exam Preparation.
- On the Blog: My Other Blog Posts on Certifications.
- On the Web: Oracle Certification Program.
OCA, OCP, OCE, Dumps, Brain dumps, Practice Questions, Sample Questions, Cheat sheet, Test papers.
I have been given with a challenging task to convert one of our critical production databases, which is of 1 TB (Terabyte) in size, to Oracle 10g RAC with ASM storage option. Even though, there are many methods and tools available to perform this activity, I have preferred to use the RCONFIG tool.
We prepared an input XML file required for RCONFIG tool, and run the RCONFIG utility as follows:
The conversion took almost 9 hours to complete the process, because during the conversion RMAN used only one channel per data file to backup to ASM disks. There was no chance of improving the RMAN copy process by allocating more channels in the input XML file, and also Oracle doesn’t recommend doing other changes in the input XML file.
One thing was observed during the RMAN copy that RMAN is using target database control file instead of recovery catalog, and also using the RMAN default preconfigured settings for that database.
To know the RMAN default preconfigured settings for the database:
We have changed the PRALLELISM count to 6 (it depends upon number of CPUs you have in the server).
Solution:
Following is the extract of rconfig.log file, this file is located under:
Note: For the sake of look and feel format, the above output has been trimmed neatly. You can also observer that 6 channels were being allocated, timings of backup start and end, and the success code end of the rconfig.log file.
References:
To know more about RCONFIG tool and other Metalink references on it, please take a look at the below blog post written by Mr. Syed Jaffar Hussain.
http://jaffardba.blogspot.com/2008/09/my-experience-of-converting-cross.html
Oracle 10g R2 Documentation information on RCONFIG:
http://download.oracle.com/docs/cd/B19306_01/install.102/b14205/cvrt2rac.htm#BABBAAEH
We prepared an input XML file required for RCONFIG tool, and run the RCONFIG utility as follows:
$ cd /oracle/ora102/db_1/assistants/rconfig/sampleXMLs $ rconfig ConverToRAC.xmlWhen we start the RCONFIG tool to convert the database to RAC, the RCONFIG tool initially moves all the non-ASM database files to ASM disk files, for this RCONFIG tool internally invokes RMAN utility to backup the target database to the ASM disk groups, eventually the database is converted to RAC using RCONFIG.
The conversion took almost 9 hours to complete the process, because during the conversion RMAN used only one channel per data file to backup to ASM disks. There was no chance of improving the RMAN copy process by allocating more channels in the input XML file, and also Oracle doesn’t recommend doing other changes in the input XML file.
One thing was observed during the RMAN copy that RMAN is using target database control file instead of recovery catalog, and also using the RMAN default preconfigured settings for that database.
To know the RMAN default preconfigured settings for the database:
$ export ORACLE_SID=MYPROD $ rman target / Recovery Manager: Release 10.2.0.4.0 - Production on Wed Aug 5 10:21:05 2009 Copyright (c) 1982, 2007, Oracle. All rights reserved. connected to target database: MYPROD (DBID=1131234567) RMAN> show all; using target database control file instead of recovery catalog RMAN configuration parameters are: CONFIGURE RETENTION POLICY TO REDUNDANCY 1; # default CONFIGURE BACKUP OPTIMIZATION OFF; # default CONFIGURE DEFAULT DEVICE TYPE TO DISK; # default CONFIGURE CONTROLFILE AUTOBACKUP OFF; # default CONFIGURE CONTROLFILE AUTOBACKUP FORMAT FOR DEVICE TYPE DISK TO '%F'; # default CONFIGURE DEVICE TYPE DISK PARALLELISM 1 BACKUP TYPE TO BACKUPSET; CONFIGURE DATAFILE BACKUP COPIES FOR DEVICE TYPE DISK TO 1; # default CONFIGURE ARCHIVELOG BACKUP COPIES FOR DEVICE TYPE DISK TO 1; # default CONFIGURE MAXSETSIZE TO UNLIMITED; # default CONFIGURE ENCRYPTION FOR DATABASE OFF; # default CONFIGURE ENCRYPTION ALGORITHM 'AES128'; # default CONFIGURE ARCHIVELOG DELETION POLICY TO NONE; # default CONFIGURE SNAPSHOT CONTROLFILE NAME TO '/oracle/ora102/db_1/dbs/snapcf_T24MIG1.f'; # defaultHere we see that the PARALLELISM is 1 (default), that’s why the RMAN using only one channel during backing up the non-ASM datafiles to ASM Disk Groups, and were taking 9 hours to complete the backup.
We have changed the PRALLELISM count to 6 (it depends upon number of CPUs you have in the server).
Solution:
RMAN> CONFIGURE DEVICE TYPE DISK PARALLELISM 6; old RMAN configuration parameters: CONFIGURE DEVICE TYPE DISK PARALLELISM 1 BACKUP TYPE TO BACKUPSET; new RMAN configuration parameters: CONFIGURE DEVICE TYPE DISK PARALLELISM 6 BACKUP TYPE TO BACKUPSET; new RMAN configuration parameters are successfully stored RMAN> show all; RMAN configuration parameters are: CONFIGURE RETENTION POLICY TO REDUNDANCY 1; # default CONFIGURE BACKUP OPTIMIZATION OFF; # default CONFIGURE DEFAULT DEVICE TYPE TO DISK; # default CONFIGURE CONTROLFILE AUTOBACKUP OFF; # default CONFIGURE CONTROLFILE AUTOBACKUP FORMAT FOR DEVICE TYPE DISK TO '%F'; # default CONFIGURE DEVICE TYPE DISK PARALLELISM 6 BACKUP TYPE TO BACKUPSET; CONFIGURE DATAFILE BACKUP COPIES FOR DEVICE TYPE DISK TO 1; # default CONFIGURE ARCHIVELOG BACKUP COPIES FOR DEVICE TYPE DISK TO 1; # default CONFIGURE MAXSETSIZE TO UNLIMITED; # default CONFIGURE ENCRYPTION FOR DATABASE OFF; # default CONFIGURE ENCRYPTION ALGORITHM 'AES128'; # default CONFIGURE ARCHIVELOG DELETION POLICY TO NONE; # default CONFIGURE SNAPSHOT CONTROLFILE NAME TO '/oracle/ora102/db_1/dbs/snapcf_T24MIG1.f'; # defaultAfter changing the PARALLELISM count to 6, the RMAN has allocated 6 channels and the conversion process has improved greatly and reduced the downtime drastically to 4 Hours 30 minutes.
Following is the extract of rconfig.log file, this file is located under:
$ORACLE_HOME/db_1/cfgtoolslogs/rconfig ............................................................................ ............................................................................ ............................................................................ [17:17:16:43] Log RMAN Output=RMAN> backup as copy database to destination '+DATA_DG'; [17:17:16:53] Log RMAN Output=Starting backup at 04-AUG-09 [17:17:16:258] Log RMAN Output=using target database control file instead of recovery catalog [17:17:16:694] Log RMAN Output=allocated channel: ORA_DISK_1 [17:17:16:698] Log RMAN Output=channel ORA_DISK_1: sid=866 devtype=DISK [17:17:17:9] Log RMAN Output=allocated channel: ORA_DISK_2 [17:17:17:13] Log RMAN Output=channel ORA_DISK_2: sid=865 devtype=DISK [17:17:17:324] Log RMAN Output=allocated channel: ORA_DISK_3 [17:17:17:327] Log RMAN Output=channel ORA_DISK_3: sid=864 devtype=DISK [17:17:17:637] Log RMAN Output=allocated channel: ORA_DISK_4 [17:17:17:641] Log RMAN Output=channel ORA_DISK_4: sid=863 devtype=DISK [17:17:17:967] Log RMAN Output=allocated channel: ORA_DISK_5 [17:17:17:971] Log RMAN Output=channel ORA_DISK_5: sid=862 devtype=DISK [17:17:18:288] Log RMAN Output=allocated channel: ORA_DISK_6 [17:17:18:293] Log RMAN Output=channel ORA_DISK_6: sid=861 devtype=DISK [17:17:20:416] Log RMAN Output=channel ORA_DISK_1: starting datafile copy [17:17:20:427] Log RMAN Output=input datafile fno=00053 name=/oradata/MYPROD/users_01.dbf [17:17:20:532] Log RMAN Output=channel ORA_DISK_2: starting datafile copy [17:17:20:544] Log RMAN Output=input datafile fno=00021 name=/oradata/MYPROD/ users_02.dbf [17:17:20:680] Log RMAN Output=channel ORA_DISK_3: starting datafile copy [17:17:20:694] Log RMAN Output=input datafile fno=00022 name=/oradata/MYPROD/ users_03.dbf [17:17:20:786] Log RMAN Output=channel ORA_DISK_4: starting datafile copy [17:17:20:800] Log RMAN Output=input datafile fno=00023 name=/oradata/MYPROD/ users_04.dbf [17:17:20:855] Log RMAN Output=channel ORA_DISK_5: starting datafile copy [17:17:20:868] Log RMAN Output=input datafile fno=00024 name=/oradata/MYPROD/ users_05.dbf [17:17:20:920] Log RMAN Output=channel ORA_DISK_6: starting datafile copy [17:17:20:930] Log RMAN Output=input datafile fno=00011 name=/oradata/MYPROD/ users_06.dbf ............................................................................ ............................................................................ ............................................................................ [21:29:5:518] Log RMAN Output=Finished backup at 04-AUG-09 ............................................................................ ............................................................................ ............................................................................ [21:39:10:723] [NetConfig.startListenerResources:5] started Listeners associated with database MYPROD [21:39:10:723] [Step.execute:255] STEP Result=Operation Succeeded [21:39:10:724] [Step.execute:284] Returning result:Operation Succeeded [21:39:10:724] [RConfigEngine.execute:68] bAsyncJob=false [21:39:10:725] [RConfigEngine.execute:77] Result= < version="1.1">
<ConvertToRAC>
<Convert>
<Response>
<Result code="0" >
Operation Succeeded
</Result>
</Response>
<ReturnValue type="object">
<Oracle_Home>
/oracle/ora102/db_1
</Oracle_Home>
<SIDList>
<SID>MYPROD1<\SID>
<SID>MYPROD2<\SID>
<\SIDList> </ReturnValue>
</Convert>
</ConvertToRAC></RConfig>Note: For the sake of look and feel format, the above output has been trimmed neatly. You can also observer that 6 channels were being allocated, timings of backup start and end, and the success code end of the rconfig.log file.
References:
To know more about RCONFIG tool and other Metalink references on it, please take a look at the below blog post written by Mr. Syed Jaffar Hussain.
http://jaffardba.blogspot.com/2008/09/my-experience-of-converting-cross.html
Oracle 10g R2 Documentation information on RCONFIG:
http://download.oracle.com/docs/cd/B19306_01/install.102/b14205/cvrt2rac.htm#BABBAAEH
There seems to be a misunderstanding that a MOUNT actually verifies datafiles.
A STARTUP MOUNT (or STARTUP NOMOUNT followed by ALTER DATABASE MOUNT) does *NOT* read the datafiles and/or verify them. It does read the controlfile(s).
Here's a simple test :
I have a tablespace with a datafile that is "ONLINE". A STARTUP MOUNT (or STARTUP NOMOUNT followed by ALTER DATABASE MOUNT) does *NOT* read the datafiles and/or verify them. It does read the controlfile(s).
Here's a simple test :
SQL> create tablespace X_TBS datafile '/tmp/X_TBS.dbf' size 50M;
Tablespace created.
SQL> create table hemant.X_TBS (col_1) tablespace X_TBS
2 as select rownum from dual connect by level < 100;
Table created.
SQL>
SQL> select file#, status, name
2 from v$datafile
3 where name like '%X_TBS%';
FILE# STATUS NAME
---------- ------- ----------------------------------------
14 ONLINE /tmp/X_TBS.dbf
SQL> select file#, status, name
2 from v$datafile_header
3 where name like '%X_TBS%';
FILE# STATUS NAME
---------- ------- ----------------------------------------
14 ONLINE /tmp/X_TBS.dbf
SQL> select owner, segment_name, bytes/1024
2 from dba_segments
3 where tablespace_name = 'X_TBS';
OWNER
------------------------------
SEGMENT_NAME
--------------------------------------------------------------------------------
BYTES/1024
----------
HEMANT
X_TBS
64
SQL>
I now shutdown the database instance and remove the datafile : SQL> shutdown immediate Database closed. Database dismounted. ORACLE instance shut down. SQL> !ls /tmp/X_TBS.dbf /tmp/X_TBS.dbf SQL> !rm /tmp/X_TBS.dbf SQL> !ls /tmp/X_TBS.dbf ls: /tmp/X_TBS.dbf: No such file or directory SQL>Does the STARTUP MOUNT succeed ?
SQL> startup mount ORACLE instance started. Total System Global Area 535662592 bytes Fixed Size 1337720 bytes Variable Size 213911176 bytes Database Buffers 314572800 bytes Redo Buffers 5840896 bytes Database mounted. SQL> SQL> shutdown ORA-01109: database not open Database dismounted. ORACLE instance shut down. SQL> startup nomount; ORACLE instance started. Total System Global Area 535662592 bytes Fixed Size 1337720 bytes Variable Size 213911176 bytes Database Buffers 314572800 bytes Redo Buffers 5840896 bytes SQL> alter database mount; Database altered. SQL>Can the file be listed ? Yes. However, V$DATAFILE_HEADER no longer shows the name ! The query on V$DATAFILE_HEADER does cause Oracle to "look" for the file but it does NOT cause a failure. It simply finds it "missing".
SQL> select file#, status, name
2 from v$datafile
3 where file#=14;
FILE# STATUS NAME
---------- ------- ----------------------------------------
14 ONLINE /tmp/X_TBS.dbf
SQL> select file#, status, name
2 from v$datafile_header
3 where file#=14;
FILE# STATUS NAME
---------- ------- ----------------------------------------
14 ONLINE
SQL>
When does Oracle attempt to access the datafile ? SQL> alter database open; alter database open * ERROR at line 1: ORA-01157: cannot identify/lock data file 14 - see DBWR trace file ORA-01110: data file 14: '/tmp/X_TBS.dbf' SQL>Even as the OPEN failed with an ORA-01157, the datafile is present in the controlfile :
SQL> select file#, status, name
2 from v$datafile
3 where file#=14;
FILE# STATUS NAME
---------- ------- ----------------------------------------
14 ONLINE /tmp/X_TBS.dbf
SQL> select file#, status, name
2 from v$datafile_header
3 where file#=14;
FILE# STATUS NAME
---------- ------- ----------------------------------------
14 ONLINE
SQL>
I hope that I have you convinced that a MOUNT does NOT verify the datafiles. If you are still not convinced, read the Backup and Recovery documentation about how to do a FULL DATABASE RESTORE and RECOVER -- where you restore the controlfile and mount the database before you even restore datafiles. How would the MOUNT succeed with the controlfile alone ?Now, here's something more. You'd understand this if you understand how RECOVER works. Do NOT try this if you are not sure about how I was able to "recreate" the datafile. Do NOT try this if you do not know how data is inserted in the X_TBS table when the database is in NOARCHIVELOG mode.
SQL> alter database create datafile 14 as '/tmp/new_X_TBS.dbf';
Database altered.
SQL> recover datafile 14;
Media recovery complete.
SQL> select file#, status, name
2 from v$datafile
3 where file#=14;
FILE# STATUS NAME
---------- ------- ----------------------------------------
14 ONLINE /tmp/new_X_TBS.dbf
SQL> select file#, status, name
2 from v$datafile_header
3 where file#=14;
FILE# STATUS NAME
---------- ------- ----------------------------------------
14 ONLINE /tmp/new_X_TBS.dbf
SQL> alter database open;
Database altered.
SQL> select tablespace_name from dba_tables
2 where owner = 'HEMANT'
3 and table_name = 'X_TBS';
TABLESPACE_NAME
------------------------------
X_TBS
SQL>
SQL> select file_name from dba_data_files
2 where file_id=14;
FILE_NAME
--------------------------------------------------------------------------------
/tmp/new_X_TBS.dbf
SQL>
SQL> select count(*) from hemant.X_TBS;
select count(*) from hemant.X_TBS
*
ERROR at line 1:
ORA-01578: ORACLE data block corrupted (file # 14, block # 131)
ORA-01110: data file 14: '/tmp/new_X_TBS.dbf'
ORA-26040: Data block was loaded using the NOLOGGING option
SQL>
Happy simulating and testing on your own database. Whenever we do an Incomplete Recovery (recovery until CANCEL or until a specific SCN/CHANGE#, SEQUENCE# or TIME), we have to OPEN the database with a RESETLOGS.
RESETLOGS_TIME has to be indicated by Oracle if we were to query the database later. This is the time when the RESETLOGS was issued. RESETLOGS_CHANGE# is the SCN for the database at the issuance of the command. Oracle also provides information of the RESETLOGS_ID for each "incarnation". A RESETLOGS creates a new "incarnation" of the database.
Thus, my database has this information :
RESETLOGS_TIME has to be indicated by Oracle if we were to query the database later. This is the time when the RESETLOGS was issued. RESETLOGS_CHANGE# is the SCN for the database at the issuance of the command. Oracle also provides information of the RESETLOGS_ID for each "incarnation". A RESETLOGS creates a new "incarnation" of the database.
Thus, my database has this information :
SQL> select sysdate from dual;
SYSDATE
---------
29-JAN-12
SQL> select resetlogs_time from v$database;
RESETLOGS
---------
01-JAN-12
SQL> select incarnation#, resetlogs_change#, resetlogs_time, resetlogs_id
2 from v$database_incarnation
3 order by 1;
INCARNATION# RESETLOGS_CHANGE# RESETLOGS RESETLOGS_ID
------------ ----------------- --------- ------------
1 1 13-AUG-09 694825248
2 754488 30-OCT-09 701609923
3 4955792 01-JAN-12 771419578
4 4957614 01-JAN-12 771421939
SQL>
SQL> l
1 select sequence#, trunc(first_time)
2 from v$archived_log
3 where first_time > to_date('31-DEC-11','DD-MON-RR')
4* order by 1
SQL> /
SEQUENCE# TRUNC(FIR
---------- ---------
1 01-JAN-12
1 01-JAN-12
1 01-JAN-12
1 01-JAN-12
1 01-JAN-12
2 01-JAN-12
2 01-JAN-12
2 14-JAN-12
2 01-JAN-12
2 01-JAN-12
3 01-JAN-12
3 01-JAN-12
3 15-JAN-12
3 01-JAN-12
4 15-JAN-12
5 15-JAN-12
180 01-JAN-12
180 01-JAN-12
180 01-JAN-12
181 01-JAN-12
181 01-JAN-12
181 01-JAN-12
182 01-JAN-12
182 01-JAN-12
24 rows selected.
SQL>
It does seem very confusing to have SEQUENCE#1 to SEQUENCE#3 report 5 entries each. And why is there a gap between SEQUENCE#5 and SEQUENCE#180 ? Can we dig deeper ?SQL> select resetlogs_id, sequence#, trunc(first_time) 2 from v$archived_log 3 order by 1,2 4 / RESETLOGS_ID SEQUENCE# TRUNC(FIR ------------ ---------- --------- 701609923 179 26-DEC-11 701609923 180 01-JAN-12 701609923 180 01-JAN-12 701609923 180 01-JAN-12 701609923 181 01-JAN-12 701609923 181 01-JAN-12 701609923 181 01-JAN-12 701609923 182 01-JAN-12 701609923 182 01-JAN-12 771419578 1 01-JAN-12 771419578 1 01-JAN-12 771419578 1 01-JAN-12 771419578 1 01-JAN-12 771419578 2 01-JAN-12 771419578 2 01-JAN-12 771419578 2 01-JAN-12 771419578 2 01-JAN-12 771419578 3 01-JAN-12 771419578 3 01-JAN-12 771419578 3 01-JAN-12 771421939 1 01-JAN-12 771421939 2 14-JAN-12 771421939 3 15-JAN-12 771421939 4 15-JAN-12 771421939 5 15-JAN-12 25 rows selected. SQL>Now, I can see that the SEQUENCE# 179 to 182 are for 26-DEC-11 to 01-JAN-12 for INCARNATION#2 which existed from 30-OCT-09 to 01-JAN-12 (this information is retrieved from V$DATABASE_INCARNATION from the earlier query). Yet, there are repeated entries from the same SEQUENCE# (180 and 181 have three entries each while 182 has two entries) ! Was each log file archived more than once ? Similarly, in INCARNATION#3 I have three entries for each of SEQUENCE# 1 to 3. Then, the latest INCARNATION#4 (for RESETLOGS_ID 771421939) has only 1 entry each for SEQUENCE# 1 to 5.
Were there really multiple archivelogs created from SEQUENCE# 180 to 182 and again for 1 to 3 on 01-JAN-12 ?
[oracle@linux64 2012_01_01]$ pwd /home/oracle/app/oracle/flash_recovery_area/ORCL/archivelog/2012_01_01 [oracle@linux64 2012_01_01]$ ls -ltr total 10200 -rw-rw---- 1 oracle oracle 5261824 Jan 1 10:59 o1_mf_1_179_7hzlzvcg_.arc -rw-rw---- 1 oracle oracle 90112 Jan 1 11:00 o1_mf_1_180_7hzm1ogl_.arc -rw-rw---- 1 oracle oracle 483840 Jan 1 11:02 o1_mf_1_181_7hzm5frg_.arc -rw-rw---- 1 oracle oracle 377856 Jan 1 11:12 o1_mf_1_182_7hzmst65_.arc -rw-rw---- 1 oracle oracle 483840 Jan 1 11:12 o1_mf_1_181_7hzmst4n_.arc -rw-rw---- 1 oracle oracle 90112 Jan 1 11:12 o1_mf_1_180_7hzmst70_.arc -rw-rw---- 1 oracle oracle 1486336 Jan 1 11:25 o1_mf_1_1_7hznjsy3_.arc -rw-rw---- 1 oracle oracle 15872 Jan 1 11:26 o1_mf_1_2_7hznmzh7_.arc -rw-rw---- 1 oracle oracle 590848 Jan 1 11:52 o1_mf_1_3_7hzp3my5_.arc -rw-rw---- 1 oracle oracle 15872 Jan 1 11:52 o1_mf_1_2_7hzp3mxw_.arc -rw-rw---- 1 oracle oracle 1486336 Jan 1 11:52 o1_mf_1_1_7hzp3mvq_.arc [oracle@linux64 2012_01_01]$That's curious ! I dont' see three archivelog files, but I do see two archivelogs for SEQUENCE# 180 and 181 and 1 and 2!!
Can anyone explain this ?
Hint : I did an OPEN RESETLOGS.
.
.
UPDATE 06-Feb :
Since there hasn't been a response ....
some more information ...
SQL> l
1 select sequence#, resetlogs_id,
2 to_char(first_time,'DD-MON HH24:MI:SS'), to_char(completion_time,'DD-MON HH24:MI:SS'),
3 nvl(name,'Name is a NULL')
4 from v$archived_log
5 where sequence# in (1,2,3,180,181,182)
6* order by sequence#, resetlogs_id, completion_time
SQL> /
SEQUENCE# RESETLOGS_ID TO_CHAR(FIRST_TIME,'DD-M TO_CHAR(COMPLETION_TIME,
---------- ------------ ------------------------ ------------------------
NVL(NAME,'NAMEISANULL')
--------------------------------------------------------------------------------
1 771419578 01-JAN 11:12:58 01-JAN 11:25:14
/home/oracle/app/oracle/flash_recovery_area/ORCL/archivelog/2012_01_01/o1_mf_1_1
_7hznjsy3_.arc
1 771419578 01-JAN 11:12:58 01-JAN 11:48:44
Name is a NULL
1 771419578 01-JAN 11:12:58 01-JAN 11:50:00
/home/oracle/app/oracle/oradata/orcl/redo01.log
1 771419578 01-JAN 11:12:58 01-JAN 11:52:19
/home/oracle/app/oracle/flash_recovery_area/ORCL/archivelog/2012_01_01/o1_mf_1_1
_7hzp3mvq_.arc
1 771421939 01-JAN 11:52:19 14-JAN 23:48:56
/home/oracle/app/oracle/flash_recovery_area/ORCL/archivelog/2012_01_14/o1_mf_1_1
_7k38z82o_.arc
2 771419578 01-JAN 11:25:13 01-JAN 11:26:55
/home/oracle/app/oracle/flash_recovery_area/ORCL/archivelog/2012_01_01/o1_mf_1_2
_7hznmzh7_.arc
2 771419578 01-JAN 11:25:13 01-JAN 11:48:44
Name is a NULL
2 771419578 01-JAN 11:25:13 01-JAN 11:50:00
/home/oracle/app/oracle/oradata/orcl/redo02.log
2 771419578 01-JAN 11:25:13 01-JAN 11:52:19
/home/oracle/app/oracle/flash_recovery_area/ORCL/archivelog/2012_01_01/o1_mf_1_2
_7hzp3mxw_.arc
2 771421939 14-JAN 23:48:55 15-JAN 22:47:38
/home/oracle/app/oracle/flash_recovery_area/ORCL/archivelog/2012_01_15/o1_mf_1_2
_7k5srb64_.arc
3 771419578 01-JAN 11:26:55 01-JAN 11:48:44
Name is a NULL
3 771419578 01-JAN 11:26:55 01-JAN 11:50:00
/home/oracle/app/oracle/oradata/orcl/redo03.log
3 771419578 01-JAN 11:26:55 01-JAN 11:52:19
/home/oracle/app/oracle/flash_recovery_area/ORCL/archivelog/2012_01_01/o1_mf_1_3
_7hzp3my5_.arc
3 771421939 15-JAN 22:47:38 15-JAN 23:14:40
/home/oracle/app/oracle/flash_recovery_area/ORCL/archivelog/2012_01_15/o1_mf_1_3
_7k5vc0nf_.arc
180 701609923 01-JAN 10:59:07 01-JAN 11:00:05
/home/oracle/app/oracle/flash_recovery_area/ORCL/archivelog/2012_01_01/o1_mf_1_1
80_7hzm1ogl_.arc
180 701609923 01-JAN 10:59:07 01-JAN 11:11:00
Name is a NULL
180 701609923 01-JAN 10:59:07 01-JAN 11:12:58
/home/oracle/app/oracle/flash_recovery_area/ORCL/archivelog/2012_01_01/o1_mf_1_1
80_7hzmst70_.arc
181 701609923 01-JAN 11:00:05 01-JAN 11:08:38
/home/oracle/app/oracle/flash_recovery_area/ORCL/archivelog/2012_01_01/o1_mf_1_1
81_7hzm5frg_.arc
181 701609923 01-JAN 11:00:05 01-JAN 11:11:00
Name is a NULL
181 701609923 01-JAN 11:00:05 01-JAN 11:12:58
/home/oracle/app/oracle/flash_recovery_area/ORCL/archivelog/2012_01_01/o1_mf_1_1
81_7hzmst4n_.arc
182 701609923 01-JAN 11:02:05 01-JAN 11:11:00
Name is a NULL
182 701609923 01-JAN 11:02:05 01-JAN 11:12:58
/home/oracle/app/oracle/flash_recovery_area/ORCL/archivelog/2012_01_01/o1_mf_1_1
82_7hzmst65_.arc
22 rows selected.
SQL>
Look at the number of occurrences of SEQUENCE#1. Check the COMPLETION TIME for these entries. Why is the NAME a NULL value for some occurrences ? ..... OK .... since it is unlikely that anyone will yet reply to the latest question .....
Here's more information from the alert.log :
Sun Jan 01 11:25:13 2012 ALTER SYSTEM ARCHIVE LOG Sun Jan 01 11:25:13 2012 Thread 1 advanced to log sequence 2 (LGWR switch) Current log# 2 seq# 2 mem# 0: /home/oracle/app/oracle/oradata/orcl/redo02.log Sun Jan 01 11:25:14 2012 Archived Log entry 10 added for thread 1 sequence 1 ID 0x4d6fd925 dest 1: Sun Jan 01 11:33:24 2012 alter database mount Sun Jan 01 11:33:28 2012 Successful mount of redo thread 1, with mount id 1299165956 Database mounted in Exclusive Mode Lost write protection disabled Completed: alter database mount Sun Jan 01 11:35:19 2012 Errors in file /home/oracle/app/oracle/diag/rdbms/orcl/orcl/trace/orcl_m000_4414.trc: ORA-27037: unable to obtain file status Linux Error: 13: Permission denied Additional information: 3 ORA-01122: database file 14 failed verification check ORA-01110: data file 14: '/oradata/add_tbs.dbf' ORA-01565: error in identifying file '/oradata/add_tbs.dbf' ORA-27037: unable to obtain file status Linux Error: 13: Permission denied Additional information: 3 Checker run found 1 new persistent data failures Sun Jan 01 11:36:21 2012 Errors in file /home/oracle/app/oracle/diag/rdbms/orcl/orcl/trace/orcl_m000_4427.trc: ORA-27037: unable to obtain file status Linux Error: 13: Permission denied Additional information: 3 ORA-01122: database file 14 failed verification check ORA-01110: data file 14: '/oradata/add_tbs.dbf' ORA-01565: error in identifying file '/oradata/add_tbs.dbf' ORA-27037: unable to obtain file status Linux Error: 13: Permission denied Additional information: 3 Sun Jan 01 11:36:23 2012 Full restore complete of datafile 7 /home/oracle/app/oracle/oradata/orcl/FLOW_1146416395631714.dbf. Elapsed time: 0:00:00 checkpoint is 4956847 last deallocation scn is 960623 Full restore complete of datafile 4 /home/oracle/app/oracle/oradata/orcl/users01.dbf. Elapsed time: 0:00:08 checkpoint is 4956847 last deallocation scn is 4932522 Sun Jan 01 11:36:38 2012 Full restore complete of datafile 6 /home/oracle/app/oracle/oradata/orcl/FLOW_1046101119510758.dbf. Elapsed time: 0:00:00 checkpoint is 4956853 last deallocation scn is 833081 Full restore complete of datafile 8 /home/oracle/app/oracle/oradata/orcl/FLOW_1170420963682633.dbf. Elapsed time: 0:00:01 checkpoint is 4956853 last deallocation scn is 969921 Full restore complete of datafile 5 /home/oracle/app/oracle/oradata/orcl/example01.dbf. Elapsed time: 0:00:03 checkpoint is 4956853 last deallocation scn is 985357 Full restore complete of datafile 9 /home/oracle/app/oracle/oradata/orcl/FLOW_1194425963955800.dbf. Elapsed time: 0:00:01 checkpoint is 4956856 last deallocation scn is 976123 Full restore complete of datafile 10 /home/oracle/app/oracle/oradata/orcl/FLOW_1218408858999342.dbf. Elapsed time: 0:00:01 checkpoint is 4956856 last deallocation scn is 981657 Full restore complete of datafile 11 /home/oracle/app/oracle/oradata/orcl/FLOW_1242310449730067.dbf. Elapsed time: 0:00:01 checkpoint is 4956856 last deallocation scn is 1367698 Full restore complete of datafile 12 /home/oracle/app/oracle/oradata/orcl/FLOW_1266412439758696.dbf. Elapsed time: 0:00:01 checkpoint is 4956856 last deallocation scn is 2558126 Full restore complete of datafile 13 /home/oracle/app/oracle/oradata/orcl/APEX_1295922881855015.dbf. Elapsed time: 0:00:01 checkpoint is 4956856 Sun Jan 01 11:37:41 2012 Signalling error 1152 for datafile 4! Signalling error 1152 for datafile 5! Signalling error 1152 for datafile 6! Signalling error 1152 for datafile 7! Signalling error 1152 for datafile 8! Signalling error 1152 for datafile 9! Signalling error 1152 for datafile 10! Signalling error 1152 for datafile 11! Signalling error 1152 for datafile 12! Signalling error 1152 for datafile 13! Errors in file /home/oracle/app/oracle/diag/rdbms/orcl/orcl/trace/orcl_m000_4436.trc: ORA-27037: unable to obtain file status Linux Error: 13: Permission denied Additional information: 3 ORA-01122: database file 14 failed verification check ORA-01110: data file 14: '/oradata/add_tbs.dbf' ORA-01565: error in identifying file '/oradata/add_tbs.dbf' ORA-27037: unable to obtain file status Linux Error: 13: Permission denied Additional information: 3 Checker run found 12 new persistent data failures Sun Jan 01 11:41:53 2012 Signalling error 1152 for datafile 4! Signalling error 1152 for datafile 5! Signalling error 1152 for datafile 6! Signalling error 1152 for datafile 7! Signalling error 1152 for datafile 8! Signalling error 1152 for datafile 9! Signalling error 1152 for datafile 10! Signalling error 1152 for datafile 11! Sun Jan 01 11:44:09 2012 Full restore complete of datafile 1 /home/oracle/app/oracle/oradata/orcl/system01.dbf. Elapsed time: 0:01:09 checkpoint is 4956816 last deallocation scn is 2681676 Undo Optimization current scn is 4717725 Sun Jan 01 11:45:38 2012 Full restore complete of datafile 2 /home/oracle/app/oracle/oradata/orcl/sysaux01.dbf. Elapsed time: 0:01:13 checkpoint is 4956816 last deallocation scn is 4862545 Sun Jan 01 11:45:57 2012 Full restore complete of datafile 3 /home/oracle/app/oracle/oradata/orcl/undotbs01.dbf. Elapsed time: 0:00:10 checkpoint is 4956816 last deallocation scn is 4718440 Undo Optimization current scn is 4717725 Sun Jan 01 11:48:02 2012 Full restore complete of datafile 14 to datafile copy /home/oracle/app/oracle/oradata/orcl/add_tbs.dbf. Elapsed time: 0:00:00 checkpoint is 4956816 Switch of datafile 14 complete to datafile copy checkpoint is 4956816 alter database recover datafile list clear Completed: alter database recover datafile list clear alter database recover datafile list 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 , 11 , 12 , 13 , 14 Completed: alter database recover datafile list 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 , 11 , 12 , 13 , 14 alter database recover if needed start until cancel using backup controlfile Media Recovery Start started logmerger process Parallel Media Recovery started with 4 slaves ORA-279 signalled during: alter database recover if needed start until cancel using backup controlfile ... alter database recover logfile '/home/oracle/app/oracle/flash_recovery_area/ORCL/archivelog/2012_01_01/o1_mf_1_2_7hznmzh7_.arc' Media Recovery Log /home/oracle/app/oracle/flash_recovery_area/ORCL/archivelog/2012_01_01/o1_mf_1_2_7hznmzh7_.arc Sun Jan 01 11:50:01 2012 ORA-279 signalled during: alter database recover logfile '/home/oracle/app/oracle/flash_recovery_area/ORCL/archivelog/2012_01_01/o1_mf_1_2_7hznmzh7_.arc'... alter database recover logfile '/home/oracle/app/oracle/oradata/orcl/redo03.log' Media Recovery Log /home/oracle/app/oracle/oradata/orcl/redo03.log Sun Jan 01 11:50:01 2012 Incomplete recovery applied all redo ever generated. Recovery completed through change 4957613 time 01/01/2012 11:30:06 Media Recovery Complete (orcl) Completed: alter database recover logfile '/home/oracle/app/oracle/oradata/orcl/redo03.log' Sun Jan 01 11:52:19 2012 alter database open resetlogs Archived Log entry 18 added for thread 1 sequence 1 ID 0x4d6fd925 dest 1: Archived Log entry 19 added for thread 1 sequence 2 ID 0x4d6fd925 dest 1: Archived Log entry 20 added for thread 1 sequence 3 ID 0x4d6fd925 dest 1: RESETLOGS after complete recovery through change 4957613 Resetting resetlogs activation ID 1299175717 (0x4d6fd925) Sun Jan 01 11:52:23 2012 Setting recovery target incarnation to 4 Sun Jan 01 11:52:23 2012 Assigning activation ID 1299165956 (0x4d6fb304) Sun Jan 01 11:52:24 2012 ARC2 started with pid=20, OS id=4534 Thread 1 opened at log sequence 1 Current log# 1 seq# 1 mem# 0: /home/oracle/app/oracle/oradata/orcl/redo01.log Successful open of redo thread 1
Do you notice how SEQUENCE#1 was Archive Log Entry 10 and again entry 18 after an OPEN RESETLOGS. The actual Online Redo Log files were *still present* and yet, I did an Incomplete Recovery and OPEN RESETLOGS. The Onlne Redo Log file that was present on disk was *again* archived out by Oracle (and a new activiation ID and target incarnation assigned). Thus, this was an OPEN RESETLOGS with Online Redo Logs present. Oracle automatically detected that the files were present and archived them out ! . .
What's the first step in a DR scenario? Recovering the RMAN catalog database of course!
Can you use RMAN to recover RMAN? Yes, you can!
For my money, the best feature of RMAN is that even though the catalog database itself will not startup without recovery, it can still be used. Which is great, because otherwise we have one of those dreaded Star Trek space-time paradoxes (what do you do to recover your recovery system?!), and those make my head hurt. Even better, it's really pretty easy if you know what to do.
My scenario is:
I walk into work one morning and the production box that my RMAN catalog is running on got hosed-up somehow over night (i'm not naming any names... *cough* sysadmin *cough*) and now all of the databases on the box are down and in need of recovery as well as the RMAN database.
Note that in this particular case, the RMANDB database needed archive logs that were not on the system in order to be recovered. This is what necessitates the use of Step 5 below to retrieve the file, otherwise, this step could be skipped.
Here's how we fix the RMAN catalog database:
Can you use RMAN to recover RMAN? Yes, you can!
For my money, the best feature of RMAN is that even though the catalog database itself will not startup without recovery, it can still be used. Which is great, because otherwise we have one of those dreaded Star Trek space-time paradoxes (what do you do to recover your recovery system?!), and those make my head hurt. Even better, it's really pretty easy if you know what to do.
My scenario is:
I walk into work one morning and the production box that my RMAN catalog is running on got hosed-up somehow over night (i'm not naming any names... *cough* sysadmin *cough*) and now all of the databases on the box are down and in need of recovery as well as the RMAN database.
Note that in this particular case, the RMANDB database needed archive logs that were not on the system in order to be recovered. This is what necessitates the use of Step 5 below to retrieve the file, otherwise, this step could be skipped.
Here's how we fix the RMAN catalog database:
- Set your Oracle environment variables as normal (I use "oraenv")
- $ . oraenv
- Start rman
- $ rman
- Connect to the target DB and then the catalog (I use the "rman" user as my catalog owner and i've named my RMAN catalog database "rmandb")
- RMAN> connect target
- RMAN> connect catalog rman@rmandb
- RMAN-00571: ===========================================================
RMAN-00569: =============== ERROR MESSAGE STACK FOLLOWS ===============
RMAN-00571: ===========================================================
RMAN-04004: error from recovery catalog database: ORA-01034: ORACLE not available
ORA-27101: shared memory realm does not exist
IBM AIX RISC System/6000 Error: 2: No such file or directory - Recover the database
- RMAN> startup force nomount;
- Oracle instance started
Total System Global Area 2164260864 bytes
Fixed Size 2074256 bytes
Variable Size 704645488 bytes
Database Buffers 1442840576 bytes
Redo Buffers 14700544 bytes - RMAN> alter database mount;
- database mounted
- Get the missing archive logs back from tape/disk/TSM/whatever
- NOTE: When I first tried the "startup" command the database it told me it need archive log 241 and up, so that is where the value below came from (you can always use "restore archivelog all")
- RMAN> run {
allocate channel oem_restore type sbt parms 'ENV=(TDPO_OPTFILE=/usr/tivoli/tsm/client/oracle/bin64/tdpo.opt)';
allocate channel oem_restore_disk type disk;
restore archivelog from logseq=241 thread=1;
} - Open the database
- RMAN> alter database open resetlogs;
I was browsing the Oracle Forums earlier today and this post with a bit of SQL to clear OEM alerts from mnazim, who always has good advice to offer:
To clear the alert:
1. Make a SELECT * from MGMT_CURRENT_SEVERITY and show for the TARGET_GUID, METRIC_GUID and KEY_VALUE.
2. Connect to db user SYSMAN and execute:
exec EM_SEVERITY.delete_current_severity(TARGET_GUID, METRIC_GUID, KEY_VALUE);
for example:
exec EM_SEVERITY.delete_current_severity('0DEB8E6980695B7548CF98871084AD10', 'F95BA0D95585002889E1ABF92B2DA7C3', 'SYS');
Have you run the new Oracle 11g installer on *NIX and received a nasty message?
It happened to me this week! So, let's say you download the oracle11g installer for AIX, start x-windows (I prefer CygWin), export your display, test with xclock, then go into the "database" folder and do: ./runInstaller
These are the errors I received:
Starting Oracle Universal Installer...
Checking Temp space: must be greater than 190 MB. Actual 11907 MB Passed
Checking swap space: must be greater than 150 MB. Actual 19968 MB Passed
Checking monitor: must be configured to display at least 256 colors. Actual 16777216 Passed
Preparing to launch Oracle Universal Installer from /oracle/tmp/OraInstall2010-03-11_12-25-37PM. Please wait ...
[oracle@myserver 12:26:03] (brent01) /oracle/INSTALL/database
$ Exception in thread "main" java.lang.UnsatisfiedLinkError: /oracle/tmp/OraInstall2010-03-11_12-25-37PM/jdk/jre/bin//motif21/libmawt.a ( 0509-022 Cannot load module /oracle/tmp/OraInstall2010-03-11_12-25-37PM/jdk/jre/bin//motif21/libmawt.a.
0509-150 Dependent module /usr/lpp/X11/lib/libXt.a(shr_64.o) could not be loaded.
0509-152 Member shr_64.o is not found in archive
0509-022 Cannot load module /oracle/tmp/OraInstall2010-03-11_12-25-37PM/jdk/jre/bin//motif21/libmawt.a.
0509-150 Dependent module /oracle/tmp/OraInstall2010-03-11_12-25-37PM/jdk/jre/bin//motif21/libmawt.a could not be loaded.)
at java.lang.ClassLoader.loadLibraryWithPath(ClassLoader.java:986)
Well, that's a fine mess!
Before you comb MetaLink and create soft links to other libraries, etc. do yourself a favor and try this:
$ env | grep -i libpath
If your LIBPATH environment variable contains the system's X11 lib, then that's your problem. Mine showed:
LIBPATH=/lib:/usr/lpp/X11/lib:/oracle/oracle8i/product/8.1.7/lib
Removing "/usr/lpp/X11/lib" piece from my LIBPATH resolved the error.
$ export LIBPATH="/lib"
$ ./runInstaller
Success!
HowTo: Create a universal UDM report page in OEM
PROBLEM:
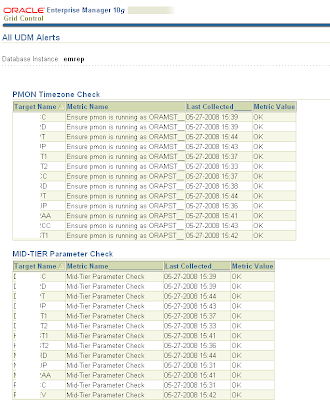
PROBLEM:
- You have a bunch of User Defined Metrics (UDM) setup in OEM, and you want to know the staus of each of them.
- OEM does not provide a single page to show the status of UDMs - users must navigate to each instance and look at the UDM page.
- Create a standard OEM Report to display all of your UDMs in one place!
- First, if you have not already discovered this the hard way, you cannot create a Report against a non-EMREP/non-Repository tables. Why, i'll never know. But, whatever. The thing is, if you try to create a report using something easy like showing how many records are in an Target Database table, it will return the error "ORA-00942: table or view does not exist"
- In this case, we are actually hitting an OEM Repository table, but it's not one of the objects we are allowed to query via the "Table From SQL" report element type.
- Fortunately, "bwolter" found a work-around for this sorry situation and published how to it in this Oracle OEM Forum post.
- Follow his 3 easy steps, then continue with my Step 5 below.
- Create a new Report and choose whatever you want for Category, etc.
- Set the "Targets" value to the "Use the specified target" radio-button and select your Repository SID
- Set the "Privileges" value to "Run report using target privileges of the report owner (SYSTEM)"
- Click the "Elements" sub-tab, then Add a new element using the new "target_user_table_from_sql" type.
- Click the "Set Parameters" icon and enter your SQL. Note that your value of KEY_VALUE will be different than mine!
SELECT DISTINCT UPPER(target_name) "Target Name", key_value || '__' "Metric Name", TO_CHAR(collection_timestamp, 'MM-DD-YYYY HH24:MI') "Last Collected_____", string_value "Metric Value" FROM sysman.em$current_metrics WHERE metric_name = 'SQLUDM' AND UPPER(key_value) LIKE 'ENSURE%' AND string_value IS NOT NULL ORDER BY 1, 2
- My KEY_VALUE (the "Name" you used for the UDM) is "Ensure PMON is running as MST", so obviously you will set your value to whatever the Name of your UDM is.
- Rinse-and-repeat Steps 8-10 for each UDM type or gorup you want to show on the Report.
- I use underscore in my column alias names to stretch the columns out for easy reading.
- During this project I found a UDM which had encountered errors and stopped running! OEM showed no indication outside of a small icon on the Instance's UDM page (nor did it send a notification). This report will save you from that potential embarrasement!!
- Here is what my final UDM Report looks like:

Here's a question that comes up often:
- How do you remove an SPFILE parameter (not change the value of, but actually purge it outright)?
- Use "ALTER SYSTEM RESET ..." (For database versions 9i and up)
- ALTER SYSTEM RESET PARAMETER SID='SID|*'
- ALTER SYSTEM RESET "_TRACE_FILES_PUBLIC" SCOPE=SPFILE SID='*';
Here's a simple approach to setting up SSH (Secure SHell) equivalency across 2 UNIX boxes. This is also known as "using SSH and SCP without passwords".
There are a variety of reasons to setup SSH equivalency across UNIX boxes. I assume you already have a desire to do so or you would not be reading this, so let's skip the sales patch and get to the howto part.
While there are scripts that do this for you (especially if you're doing this for OEM setup), this is really easy to do on your own, so forget those kludgey scripts!
NOTE: I'm using "UNIX01" and "UNIX02" below to represent 2 different UNIX boxes along with user "oracle" - you can use whatever user you want, just ensure it's the same on both boxes.
STEPS:
Test your setup as follows:
Now you can use scp and other ssh commands with ease!
There are a variety of reasons to setup SSH equivalency across UNIX boxes. I assume you already have a desire to do so or you would not be reading this, so let's skip the sales patch and get to the howto part.
While there are scripts that do this for you (especially if you're doing this for OEM setup), this is really easy to do on your own, so forget those kludgey scripts!
NOTE: I'm using "UNIX01" and "UNIX02" below to represent 2 different UNIX boxes along with user "oracle" - you can use whatever user you want, just ensure it's the same on both boxes.
STEPS:
- On UNIX01:
- Create $HOME/.ssh, if it does not already exist
- $ cd $HOME/.ssh
- Generate your RSA key (NOTE: Your path may vary!)
- /usr/bin/ssh-keygen -t rsa
- When prompted for a passphrase, just press (ENTER) (leave it blank)
- Generate your DSA key
- /usr/bin/ssh-keygen -t dsa
- When prompted for a passphrase, just press (ENTER) (leave it blank)
- Store the 2 keys into the authorized_keys file
- cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
- cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
- On UNIX02:
- Repeat steps 1-5 above
- On UNIX01:
- Copy the 2 lines from authorized_keys on UNIX02
- Add them to the authorized_keys file
- On UNIX02:
- Copy the 2 lines from authorized_keys on UNIX01
- Add them to the authorized_keys file
Test your setup as follows:
- [oracle@UNIX01] $ ssh -l oracle unix02 date
Now you can use scp and other ssh commands with ease!
After installing 11g on Windows Vista, everything works fine. The listener is up, I can connect with SQL*Plus and misc case tools, etc.
However, no other Windows box on the same network segment (and in the same Workgroup) can access the instance on Vista.
Even a simple ping from a nearby XP box fails with "request timed out."
Google searches for things like "unable to ping vista from xp", etc. yielded the usual "check these" suspects:
 So, [click], I enable that sucker. Then, since I was already here, I created a new rule (the "Add port..." button) for port 1522:
So, [click], I enable that sucker. Then, since I was already here, I created a new rule (the "Add port..." button) for port 1522:

However, no other Windows box on the same network segment (and in the same Workgroup) can access the instance on Vista.
Even a simple ping from a nearby XP box fails with "request timed out."
Google searches for things like "unable to ping vista from xp", etc. yielded the usual "check these" suspects:
- Workgroup name is the same
- Simple file sharing is on
- Network discovery is on
- Network is Private
All check out on both boxes for me. I even have both Windows Firewalls disabled, and neither computer has McAfee or Norton, so that's not it.
Finally after 2 days or trying, I figure it's time to do a Crazy Ivan. This is Microsoft we're dealing with... so, I do something crazy; I turn on the Windows Firewall on Vista. I then clicked over to the second tab on the Firewall dialog and looked thru the checklists.
Do you know what I noticed? The "File and Printer Sharing" checkbox isn't checked. (Thanks Microsoft for letting me enable file sharing in the Network and Sharing Center and not telling me it was off in the firewall!)

Now it's back to the XP box again... and VOILA! the ping starts working. I can even ping the Vista box by it's Windows name (that failed before). More importantly, I can connect to the ORCL database on vista from XP now!
So, I ~200,000 results in Google for "unable to ping Vista from XP" and it's as simple as a checkbox or two. This is a newer Vista install, so it appears that this checkbox is off by default, couple that with the inability of Vista to warn you when you enable file sharing, and I can see why almost a quarter million people are going "WTF?!"
What is ENUM?
ENUM is short for enumeration. Its a useful programming type that contains an ordered list of string values. The programmer can define the valid values depending on their application.
Some good examples of ENUMs would be days and months, or something like directions ('North', 'South', 'East', 'West').
Is there an Oracle 'ENUM' type?
No, not really. But there are other ways of accomplishing the same thing.
For tables, just set it to a string and add a constraint that it is within a certain set.
CREATE TABLE atable (
col1 varchar2(10),
CONSTRAINT cons_atable_col1 CHECK (col1 IN ('Monday', 'Tuesday', 'Wednesday', 'Thursday',
'Friday', 'Saturday', 'Sunday'))
);
SQL> INSERT INTO atable (col1) VALUES ('Monday');
1 row created.
SQL> INSERT INTO atable (col1) VALUES ('Blingday');
insert into atable (col1) values ('Blingday')
*
ERROR at line 1:
ORA-02290: check constraint (ROBERT.CONS_ATABLE_COL1) violated
What happens if you use this type in a procedure? Will the constraint be checked? No.
CREATE OR REPLACE PROCEDURE MyProc (in_col IN atable.col1%TYPE)
AS
BEGIN
DBMS_OUTPUT.PUT_LINE(in_col);
END;
SET SERVEROUTPUT ON;
EXEC MyProc('Monday');
EXEC MyProc('Blingday');
So can you create a package subtype for this? That would be more elegant anyway.
But according to Oracle PL/SQL Programming by Steven Feuerstein Chapter 4, I don't think you can (check comments for any refutations to this).
http://www.amazon.com/exec/obidos/ASIN/0596003811/
qid=1117039808/sr=2-1/ref=pd_bbs_b_2_1/102-9543590-3979349
I think the best thing to do in this case is to create a procedure to validate your input.
CREATE OR REPLACE PROCEDURE MyCheck (in_col IN atable.col1%TYPE)
AS
BEGIN
IF (in_col NOT IN ('Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday')) THEN
-- Throw Exception here, be sure to catch it in MyProc!!
NULL;
END IF;
END;
This approach is consistent with Steven Feuerstein's approach to programming. He suggests separating these things into separate procedures. Then when a future release of Oracle supports a concept, or when you figure out how to do it, you can make the change in a single place.
So what is a guy to do?
1. If you want to use enum in a table, use a check constraint.
2. If you want to use enum in a stored procedure, write a separate procedure to validate the input.
ENUM is short for enumeration. Its a useful programming type that contains an ordered list of string values. The programmer can define the valid values depending on their application.
Some good examples of ENUMs would be days and months, or something like directions ('North', 'South', 'East', 'West').
Is there an Oracle 'ENUM' type?
No, not really. But there are other ways of accomplishing the same thing.
For tables, just set it to a string and add a constraint that it is within a certain set.
CREATE TABLE atable (
col1 varchar2(10),
CONSTRAINT cons_atable_col1 CHECK (col1 IN ('Monday', 'Tuesday', 'Wednesday', 'Thursday',
'Friday', 'Saturday', 'Sunday'))
);
SQL> INSERT INTO atable (col1) VALUES ('Monday');
1 row created.
SQL> INSERT INTO atable (col1) VALUES ('Blingday');
insert into atable (col1) values ('Blingday')
*
ERROR at line 1:
ORA-02290: check constraint (ROBERT.CONS_ATABLE_COL1) violated
What happens if you use this type in a procedure? Will the constraint be checked? No.
CREATE OR REPLACE PROCEDURE MyProc (in_col IN atable.col1%TYPE)
AS
BEGIN
DBMS_OUTPUT.PUT_LINE(in_col);
END;
SET SERVEROUTPUT ON;
EXEC MyProc('Monday');
EXEC MyProc('Blingday');
So can you create a package subtype for this? That would be more elegant anyway.
But according to Oracle PL/SQL Programming by Steven Feuerstein Chapter 4, I don't think you can (check comments for any refutations to this).
http://www.amazon.com/exec/obidos/ASIN/0596003811/
qid=1117039808/sr=2-1/ref=pd_bbs_b_2_1/102-9543590-3979349
I think the best thing to do in this case is to create a procedure to validate your input.
CREATE OR REPLACE PROCEDURE MyCheck (in_col IN atable.col1%TYPE)
AS
BEGIN
IF (in_col NOT IN ('Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday')) THEN
-- Throw Exception here, be sure to catch it in MyProc!!
NULL;
END IF;
END;
This approach is consistent with Steven Feuerstein's approach to programming. He suggests separating these things into separate procedures. Then when a future release of Oracle supports a concept, or when you figure out how to do it, you can make the change in a single place.
So what is a guy to do?
1. If you want to use enum in a table, use a check constraint.
2. If you want to use enum in a stored procedure, write a separate procedure to validate the input.
What is NOCOPY?
'NOCOPY' is an optional 'hint' to tell the PL/SQL 'compiler' not to go through the overhead of making a copy of the variable, instead just send a reference. This is generally because we don't plan on modifying it within the procedure.
My first surprise was that you couldn't use "IN NOCOPY." Isn't NOCOPY your way of telling Oracle you don't plan on messing around with the parameter? Yes, but you CAN'T mess with IN parameters, try it!
CREATE OR REPLACE PROCEDURE MyProc (in_value IN number)
AS
BEGIN
in_value := 3;
END;
PLS-00363: expression 'IN_VALUE' cannot be used as an assignment target
Therefore, it is always safe to send IN parameters by reference, making NOCOPY redundant.
My second surprise was that you had to specify NOCOPY for an OUT parameter. Because by definition isn't an OUT parameter stating that you plan on modifying the variable? Why would it be an OUT variable if you weren't touching it? So why would you NOT want NOCOPY? The answer (like so many) comes from Ask Tom:
http://asktom.oracle.com/pls/ask/f?p=4950:8:::::F4950_P8_DISPLAYID:2047154868085
Tom explains one situation where you want a copy rather than a reference for an OUT or IN OUT parameter. When you change a NOCOPY parameter, it changes right away, instead of upon successful completion of the stored procedure.
Imagine you modified the parameter, but threw an exception before successful completion. But that parameter has been changed and the calling procedure could be stuck with a bogus value.
Despite how much I trust Tom, everybody knows that I don't believe things until I see for myself. And neither should you! Besides, things change. Here's my example.
CREATE OR REPLACE PROCEDURE NoCopyProc (in_value IN OUT NOCOPY number)
AS
x number;
BEGIN
DBMS_OUTPUT.PUT_LINE(in_value || ' NoCopyProc');
in_value := 2;
x := 1/0;
END;
CREATE OR REPLACE PROCEDURE CopyProc (in_value IN OUT number)
AS
x number;
BEGIN
DBMS_OUTPUT.PUT_LINE(in_value || ' CopyProc');
in_value := 4;
x := 1/0;
END;
CREATE OR REPLACE PROCEDURE InterProc (in_value IN OUT NOCOPY number)
AS
BEGIN
IF (in_value = 1) THEN NoCopyProc(in_value);
ELSE CopyProc(in_value);
END IF;
EXCEPTION
WHEN OTHERS THEN NULL;
END;
CREATE OR REPLACE PROCEDURE MyProc
AS
the_value NUMBER(1);
BEGIN
the_value := 1;
InterProc(the_value);
DBMS_OUTPUT.PUT_LINE(the_value);
the_value := 3;
InterProc(the_value);
DBMS_OUTPUT.PUT_LINE(the_value);
END;
BEGIN MyProc; END;
1 NoCopyProc
2
3 CopyProc
3
For an excellent and more detailed overview of NOCOPY, complete with examples, restrictions and performance analysis, I once again refer you to Steven Feuerstein's writings. Although I encourage you to add his books to your collection, this chapter happens to be on-line for free:
Oracle PL/SQL Programming Guide to Oracle8i Features
http://www.unix.org.ua/orelly/oracle/guide8i/ch10_01.htm
So what is a guy to do?
Well, first of all, it was suggested to me that I should find a more gender-neutral way of summing up an article. Allow me to rephrase.
So what should we do?
1. Understand what NOCOPY means and its uses and restrictions (by following those links)
2. Take advantage of NOCOPY when you want the performance advantage of avoiding the cost of the temporary storage for OUT or IN OUT parameters.
3. Avoid NOCOPY when you don't want the side effects if the procedure fails early.
Remember, in the end, that NOCOPY is just a "hint" and Oracle will do whatever it wants anyway. Like all hints, you have to ask yourself what makes it necessary, and what makes you think Oracle is going to choose incorrectly.
'NOCOPY' is an optional 'hint' to tell the PL/SQL 'compiler' not to go through the overhead of making a copy of the variable, instead just send a reference. This is generally because we don't plan on modifying it within the procedure.
My first surprise was that you couldn't use "IN NOCOPY." Isn't NOCOPY your way of telling Oracle you don't plan on messing around with the parameter? Yes, but you CAN'T mess with IN parameters, try it!
CREATE OR REPLACE PROCEDURE MyProc (in_value IN number)
AS
BEGIN
in_value := 3;
END;
PLS-00363: expression 'IN_VALUE' cannot be used as an assignment target
Therefore, it is always safe to send IN parameters by reference, making NOCOPY redundant.
My second surprise was that you had to specify NOCOPY for an OUT parameter. Because by definition isn't an OUT parameter stating that you plan on modifying the variable? Why would it be an OUT variable if you weren't touching it? So why would you NOT want NOCOPY? The answer (like so many) comes from Ask Tom:
http://asktom.oracle.com/pls/ask/f?p=4950:8:::::F4950_P8_DISPLAYID:2047154868085
Tom explains one situation where you want a copy rather than a reference for an OUT or IN OUT parameter. When you change a NOCOPY parameter, it changes right away, instead of upon successful completion of the stored procedure.
Imagine you modified the parameter, but threw an exception before successful completion. But that parameter has been changed and the calling procedure could be stuck with a bogus value.
Despite how much I trust Tom, everybody knows that I don't believe things until I see for myself. And neither should you! Besides, things change. Here's my example.
CREATE OR REPLACE PROCEDURE NoCopyProc (in_value IN OUT NOCOPY number)
AS
x number;
BEGIN
DBMS_OUTPUT.PUT_LINE(in_value || ' NoCopyProc');
in_value := 2;
x := 1/0;
END;
CREATE OR REPLACE PROCEDURE CopyProc (in_value IN OUT number)
AS
x number;
BEGIN
DBMS_OUTPUT.PUT_LINE(in_value || ' CopyProc');
in_value := 4;
x := 1/0;
END;
CREATE OR REPLACE PROCEDURE InterProc (in_value IN OUT NOCOPY number)
AS
BEGIN
IF (in_value = 1) THEN NoCopyProc(in_value);
ELSE CopyProc(in_value);
END IF;
EXCEPTION
WHEN OTHERS THEN NULL;
END;
CREATE OR REPLACE PROCEDURE MyProc
AS
the_value NUMBER(1);
BEGIN
the_value := 1;
InterProc(the_value);
DBMS_OUTPUT.PUT_LINE(the_value);
the_value := 3;
InterProc(the_value);
DBMS_OUTPUT.PUT_LINE(the_value);
END;
BEGIN MyProc; END;
1 NoCopyProc
2
3 CopyProc
3
For an excellent and more detailed overview of NOCOPY, complete with examples, restrictions and performance analysis, I once again refer you to Steven Feuerstein's writings. Although I encourage you to add his books to your collection, this chapter happens to be on-line for free:
Oracle PL/SQL Programming Guide to Oracle8i Features
http://www.unix.org.ua/orelly/oracle/guide8i/ch10_01.htm
So what is a guy to do?
Well, first of all, it was suggested to me that I should find a more gender-neutral way of summing up an article. Allow me to rephrase.
So what should we do?
1. Understand what NOCOPY means and its uses and restrictions (by following those links)
2. Take advantage of NOCOPY when you want the performance advantage of avoiding the cost of the temporary storage for OUT or IN OUT parameters.
3. Avoid NOCOPY when you don't want the side effects if the procedure fails early.
Remember, in the end, that NOCOPY is just a "hint" and Oracle will do whatever it wants anyway. Like all hints, you have to ask yourself what makes it necessary, and what makes you think Oracle is going to choose incorrectly.
Greetings! You probably found this page either through a Search Engine, an aggregator that doesn't delete blogs for inactivity, or possibly from a site with a very long blogroll, so let me introduce myself to you.
My name is Robert Vollman. Those who were active in the on-line Oracle community from mid-2005 until mid-2007 may remember me either from this site or sites like it, from the Oracle Technology Network, DBASupport.com forums, or the Dizwell forum.
For those who joined our community more recently, I'm essentially your typical database specialist, and one who enjoys both learning more about Oracle, and in sharing that knowledge with others. I am not Oracle certified, but I've been working with Oracle (and other databases) ever since Oracle 8 about 10 years ago, and most recently I was Technical Editor on Alice Rischert's Oracle SQL By Example, 4th Edition. If you'd like to know more, I've kept all of my old articles, so I encourage you to peruse my archive.
Recently I've been of service to some of my colleagues who have been writing SQL Queries. Based on their feedback, I have helped them write faster-performing queries, in a shorter period of time, with fewer mistakes, and in such a way that maintenance was simpler. If you have found any use in what I'm about to present, you can thank them for encouraging me to dust off my blog and make another contribution to the community. Let's begin!
1. Document Clear Requirements
Some database analysts I've known have actually refused to even begin until they're given clear, documented requirements about what information is to be retrieved, and in what format.
While some of you might not be in a position to put your foot down quite so firmly, I think it's reasonable for you to insist that a certain amount of time is spent gathering and documenting requirements so that both you and those that come later know exactly what your SQL Query is/was meant to do.
Taking the time to get a solid understanding of your goal will help you carefully design your work before you begin, simultaneously reducing development time and decreasing the likelihood of errors.
2. Don't Re-invent the Wheel
Think carefully about the requirements you've been given. Unless they're really unusual, it's very possible that someone has already both seen and solved your problem.
Whether it's a pivot or crosstab query, a hierarchical query, or a task to find nearby rows, there's likely already an easy solution available. It could involve analytical functions, or something like translate or rownum/rowid.
If you're not sure, let me give you the same advice that I give frustrated strangers that find my blog and send me emails. Break down your big problem into smaller, more manageable pieces. Once you've mastered the smaller components of the requirements, start adding it all together.
3. Reduce Complexity
I remember a time when I would use the most sophisticated approach to any problem, and go home thinking I was extremely clever. Since then I've learned that sometimes you should choose to forfeit an improvement in performance if it requires an increase in complexity.
Not everyone has as sophisticated a knowledge of databases as you do, and it's foolish to create complicated queries if it's possible to write simpler ones -- especially if there's no trade-off in performance.
For just a couple of suggestions, consider using ANSI joins instead of the old-school joins, because separating your join clauses from your where clauses might make it easier for others to read. Another idea is to use views as a means to reduce the complexity of any one particular query.
4. Handle NULLs Correctly
Perhaps the most common mistake I encounter is caused by forgetting about NULLs. If someone brings me a query that is either returning rows that it shouldn't, or failing to find rows that it should, quite often it's because the query compares a field to a set value in some fashion, and the fields are NULL for the rows in question.
Databases handle NULLs are handled atypically, something I've covered several times in the past (like here and here). Provided you have this awareness, there are a lot of ways to deal with NULLs, including explicit checks (IS NULL), or something like nvl or decode.
5. Check your Types
Most of what I know I've learned either through experience, or by taking advantage of the experience of others. One of my favourites of which has always been Tom Kyte. He taught me to always be aware of my types when making comparisons: never to compare strings to dates, nor dates to strings.
Take his advice, and beware implicit conversions of dates and numbers. For more of his advice on types, check tips 9-13 in this collection of his tips.
6. Correct handling of duplicates
The next most common error when writing SQL is failing to consider how your query will handle duplicates. Sometimes you want to keep them, sometimes you only want one.
An awareness of how duplicates should be handled not only helps you write your query correctly, but it can sometimes even lead to performance boosts. For example, if you don't mind the duplicates, use UNION ALL instead of UNION.
7. Avoid Unnecessary Tuning
Performance tuning may be fun and high-profile, but most of the time it's unnecessary. Obviously you don't want to go out of your way to write sloppy SQL, but at the same time you don't need to tune your query unless you have a performance problem.
There's no harm in adopting some handy rules of thumb. For example, select only the columns you need instead of selecting *, since there may be an index that will cover your query and get you your rows faster. But if you find yourself commenting your SQL query to override the optimizer plan, then there's a very good chance that you've gone too far, and need to take a step back and find the real problem.
And don't bend over backwards trying to avoid joins. "Joins are not evil, databases were born to join," said Tom Kyte.
8. Use Bind Variables
Failure to use bind variables is one of the red flags that stand out when someone shows me a query. If you see code like this, whether it's generated dynamically or not:
SELECT something FROM somewhere WHERE something = 1234;
Then you could have a performance problem. Why? Because the exact same query with a different value (eg 4321) will be considered a different query, will not be found in the shared pool, and will require another hard parse to generate. That may not be a problem in my simple example, but it become a problem later.
Unless there's no chance a similar query will ever be written using a different value, the correct approach would be to write something like this instead:
SELECT something FROM somewhere WHERE something = :certain_something;
Now it will be found in the shared pool, require only a soft parse, and yield faster returns.
9. Use Source Control
This one is more a matter of personal preference. Ever had a query go missing? Ever had questions about a query, but didn't know who wrote it? Ever made a change to a query, screwed something up, and want to go back?
Don't keep a lot of back-up files kicking around, and don't clutter everything with needless documentation. Find and use a good, central source control repository and organise all your queries within.
10. Test, Test, Test
The three most important words in the Database world.
Furthermore, you want to test your queries on real data, with real volumes, with multiple users, and on a system that's either in use, or has simulated use closely matching the real world. Otherwise you might miss issues that only crop up in a live, high-demand system.
Well, that wraps up my list of suggestions. I really hope you found this helpful, and I'd like to thank you for reading. As always, my comments section are open, so please feel free to add more suggestions of your own, or to comment further on some of mine.
My name is Robert Vollman. Those who were active in the on-line Oracle community from mid-2005 until mid-2007 may remember me either from this site or sites like it, from the Oracle Technology Network, DBASupport.com forums, or the Dizwell forum.
For those who joined our community more recently, I'm essentially your typical database specialist, and one who enjoys both learning more about Oracle, and in sharing that knowledge with others. I am not Oracle certified, but I've been working with Oracle (and other databases) ever since Oracle 8 about 10 years ago, and most recently I was Technical Editor on Alice Rischert's Oracle SQL By Example, 4th Edition. If you'd like to know more, I've kept all of my old articles, so I encourage you to peruse my archive.
Recently I've been of service to some of my colleagues who have been writing SQL Queries. Based on their feedback, I have helped them write faster-performing queries, in a shorter period of time, with fewer mistakes, and in such a way that maintenance was simpler. If you have found any use in what I'm about to present, you can thank them for encouraging me to dust off my blog and make another contribution to the community. Let's begin!
1. Document Clear Requirements
Some database analysts I've known have actually refused to even begin until they're given clear, documented requirements about what information is to be retrieved, and in what format.
While some of you might not be in a position to put your foot down quite so firmly, I think it's reasonable for you to insist that a certain amount of time is spent gathering and documenting requirements so that both you and those that come later know exactly what your SQL Query is/was meant to do.
Taking the time to get a solid understanding of your goal will help you carefully design your work before you begin, simultaneously reducing development time and decreasing the likelihood of errors.
2. Don't Re-invent the Wheel
Think carefully about the requirements you've been given. Unless they're really unusual, it's very possible that someone has already both seen and solved your problem.
Whether it's a pivot or crosstab query, a hierarchical query, or a task to find nearby rows, there's likely already an easy solution available. It could involve analytical functions, or something like translate or rownum/rowid.
If you're not sure, let me give you the same advice that I give frustrated strangers that find my blog and send me emails. Break down your big problem into smaller, more manageable pieces. Once you've mastered the smaller components of the requirements, start adding it all together.
3. Reduce Complexity
I remember a time when I would use the most sophisticated approach to any problem, and go home thinking I was extremely clever. Since then I've learned that sometimes you should choose to forfeit an improvement in performance if it requires an increase in complexity.
Not everyone has as sophisticated a knowledge of databases as you do, and it's foolish to create complicated queries if it's possible to write simpler ones -- especially if there's no trade-off in performance.
For just a couple of suggestions, consider using ANSI joins instead of the old-school joins, because separating your join clauses from your where clauses might make it easier for others to read. Another idea is to use views as a means to reduce the complexity of any one particular query.
4. Handle NULLs Correctly
Perhaps the most common mistake I encounter is caused by forgetting about NULLs. If someone brings me a query that is either returning rows that it shouldn't, or failing to find rows that it should, quite often it's because the query compares a field to a set value in some fashion, and the fields are NULL for the rows in question.
Databases handle NULLs are handled atypically, something I've covered several times in the past (like here and here). Provided you have this awareness, there are a lot of ways to deal with NULLs, including explicit checks (IS NULL), or something like nvl or decode.
5. Check your Types
Most of what I know I've learned either through experience, or by taking advantage of the experience of others. One of my favourites of which has always been Tom Kyte. He taught me to always be aware of my types when making comparisons: never to compare strings to dates, nor dates to strings.
Take his advice, and beware implicit conversions of dates and numbers. For more of his advice on types, check tips 9-13 in this collection of his tips.
6. Correct handling of duplicates
The next most common error when writing SQL is failing to consider how your query will handle duplicates. Sometimes you want to keep them, sometimes you only want one.
An awareness of how duplicates should be handled not only helps you write your query correctly, but it can sometimes even lead to performance boosts. For example, if you don't mind the duplicates, use UNION ALL instead of UNION.
7. Avoid Unnecessary Tuning
Performance tuning may be fun and high-profile, but most of the time it's unnecessary. Obviously you don't want to go out of your way to write sloppy SQL, but at the same time you don't need to tune your query unless you have a performance problem.
There's no harm in adopting some handy rules of thumb. For example, select only the columns you need instead of selecting *, since there may be an index that will cover your query and get you your rows faster. But if you find yourself commenting your SQL query to override the optimizer plan, then there's a very good chance that you've gone too far, and need to take a step back and find the real problem.
And don't bend over backwards trying to avoid joins. "Joins are not evil, databases were born to join," said Tom Kyte.
8. Use Bind Variables
Failure to use bind variables is one of the red flags that stand out when someone shows me a query. If you see code like this, whether it's generated dynamically or not:
SELECT something FROM somewhere WHERE something = 1234;
Then you could have a performance problem. Why? Because the exact same query with a different value (eg 4321) will be considered a different query, will not be found in the shared pool, and will require another hard parse to generate. That may not be a problem in my simple example, but it become a problem later.
Unless there's no chance a similar query will ever be written using a different value, the correct approach would be to write something like this instead:
SELECT something FROM somewhere WHERE something = :certain_something;
Now it will be found in the shared pool, require only a soft parse, and yield faster returns.
9. Use Source Control
This one is more a matter of personal preference. Ever had a query go missing? Ever had questions about a query, but didn't know who wrote it? Ever made a change to a query, screwed something up, and want to go back?
Don't keep a lot of back-up files kicking around, and don't clutter everything with needless documentation. Find and use a good, central source control repository and organise all your queries within.
10. Test, Test, Test
The three most important words in the Database world.
Furthermore, you want to test your queries on real data, with real volumes, with multiple users, and on a system that's either in use, or has simulated use closely matching the real world. Otherwise you might miss issues that only crop up in a live, high-demand system.
Well, that wraps up my list of suggestions. I really hope you found this helpful, and I'd like to thank you for reading. As always, my comments section are open, so please feel free to add more suggestions of your own, or to comment further on some of mine.
Subscribe to:
Posts (Atom)
Popular Posts
-
What is ENUM? ENUM is short for enumeration. Its a useful programming type that contains an ordered list of string values. The program...
-
A colleague asked me some questions about FIRST_ROWS and ALL_ROWS, but I'm hesitant to blog about it because it's already been done...
-
Dear Blog Readers, Every now and then I do receive e-mails from the novice DBAs saying that: “We could not perform well at the interview...
-
 HowTo: Create a universal UDM report page in OEM PROBLEM: You have a bunch of User Defined Metrics (UDM) setup in OEM, and you want to kn...
HowTo: Create a universal UDM report page in OEM PROBLEM: You have a bunch of User Defined Metrics (UDM) setup in OEM, and you want to kn... -
Have you run the new Oracle 11g installer on *NIX and received a nasty message? It happened to me this week! So, let's say you downloa...
-
REM:********************************************************************************************** REM: Script : Max 50 I/O Informations R...
-
What is NOCOPY? 'NOCOPY' is an optional 'hint' to tell the PL/SQL 'compiler' not to go through the overhead of ma...
-
This blog post is for them; those who are desperately looking for free Oracle Certification dumps. Well, you might be surprised to see the...
-
I was browsing the Oracle Forums earlier today and this post with a bit of SQL to clear OEM alerts from mnazim , who always has good advice...
-
 Having chosen Oracle SQL Developer as your preferred Oracle database tool, do you have to install and learn a new technology for supporting...
Having chosen Oracle SQL Developer as your preferred Oracle database tool, do you have to install and learn a new technology for supporting...
